Introduction
This article was created to outline some best practices while developing in Decisions. Ultimately, three aspects should always be considered when developing in Decisions: functionality, reliability, and maintainability.
General Principles
- Record project documentation while developing
Keep updated documentation on the intended function of the application and testing plans as development happens. Keep note of functions that are added, modified, and removed both in the Designer Element itself and in the Designer Folder.
- Test build logic as often as possible
Typically when building in Decisions, data must be worked by one step function before it can move on to another. Running frequent tests during development can ensure that the data being worked is always where it needs to be in the process at runtime.
- Contact Decisions Support
If there are exception errors beyond understanding within the environment, please reach out to Decisions Support at support@decisions.com.
Functionality
- Know the goal of the application being created
Is this a purchase request system that tracks precise aspects of request processing to comprise large-scale Reports and Dashboards? Is this an end-user healthcare system with interactive Forms that evaluate selections against Rule logic? Knowing the purpose and function of the overall build is a helpful first step in getting started in the platform.
- Handling sensitive values for data
For increased security with handling data, data structures that record to the database have the option to mark properties as containing PII (Personally Identifiable Information). Reference, PII Fields.
- Reusing Flow logic with Sub Flows - less does more
For maintainability purposes, use as few steps as possible to build the logic, and compartmentalize specific process steps into Sub Flows. When a Flow is created, it can be referenced from within other Flows by using the Run Sub Flow step. The step is populated with the values of the Flow it is sourcing, then appears as a regular step using those values with input mappings in the main Flow. Reference, Using Sub Flows.
Technical Practices
- To prevent the loss of progress while designing, use the Save and Checkpoint buttons on the top Action Bar as often as possible
- Globally Unique Identifier (GUID) on Designer Elements
Every Designer Element created in Decisions (Data Structures, Flows, Forms, etc.) has a globally unique identifier (GUID), that would appear in some variation as follows: a5a28b25-fb05-4a95-9414-d8de174c5609. This GUID is authoritative over the name it is given in the environment.
When two of these Decisions objects have the same GUID, the newer one will overwrite the older one. The ID of any Decisions object can be found in the right-click Action Menu of the object in the Decisions environment.
Flow Design
- Reference composite types early in the Flow
Call data structures into the Flow as early as possible so that the Change Value output mapping can be used, which will output the data from a step directly as a value of the specified structure.
- Design Flow step layout with easy maintainability
Flow readability is a large consideration when designing Flow logic. The recommended Flow structure would have the steps orchestrated from left to right, top to bottom. In addition, steps should be labeled to reflect their purpose in the Flow. The steps and arrows should be connected in a way where the process logic is in functional sequence while looking at it from the Designer view.
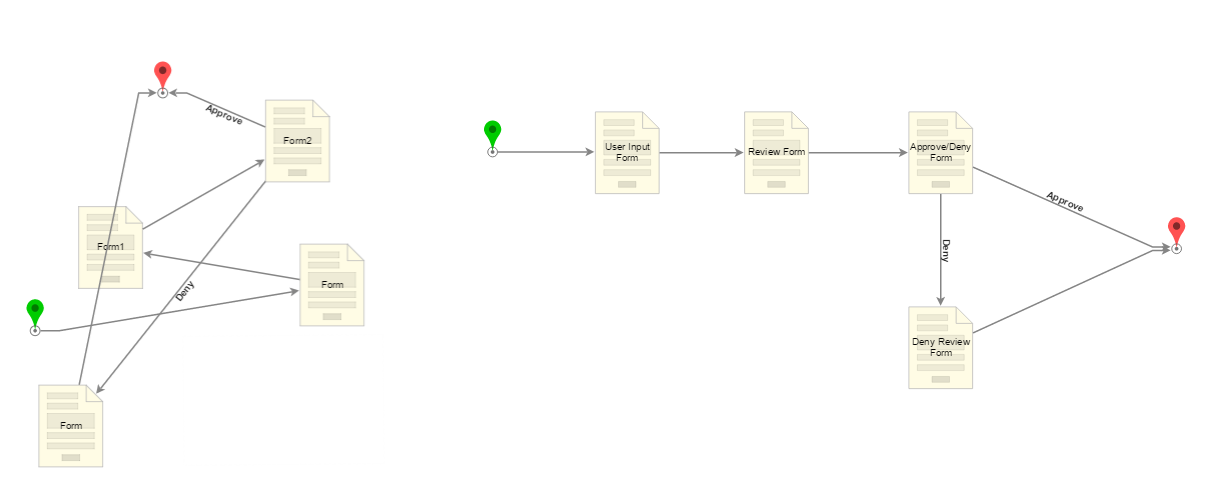
- Place steps in order of succession in logic
This Flow on the left has several steps between the Start and End step, but it is difficult to decipher where steps interact with each other or what the process does. The Flow on the right uses the addition of step labels and left to right, top to bottom organization. This Flow is easy to read and understand, for insight on both how the process works and what the steps do.
Looping/Lists
- Be mindful of recursion limits with looping
Flows limit recursions to 20,000 by default, to avoid an infinite loop that occupies all system resources. This can be changed in any Flow from within the Flow Designer, but high or unlimited recursion limits can cause performance issues. If a Flow has a recursion limit of 20,000 and it calls a Sub Flow that loops 30,000 times, this would throw an exception in the environment.
- Use ForEach looping if there is a dependency on the order of data being processed
- ForEachBreak step
When using the ForEach step in a scenario where a second list of items to iterate is fetched before a first list has completed looping, use the ForEach Break step to reset the internal counter of the ForEach step or else it will pick up on the row number that it last received.
- Run Flow For List [Batch Processiong] step
Use the Run Flow For List [Batch Processing] step if processing can happen in parallel; this step will spawn asynchronous processing threads. If the processing threads have a large workload and the rest of the parent Flow depends on the complete processing of threads, the parent Flow may need to pause processing or prevent fetching of processed data until a reasonable time. This step will force the parent Flow to move after all independent processing threads are spawned (rather than processed).
- CSV iterations with no dependencies
To iterate through a CSV with no dependencies, it is possible to forgo the “For Each Row in CSV” and do bulk processing of all rows at once using the “Run Flow for CSV” component. Large data sets (300K+ rows) have caused failures in this step.
Rules
- Utilize the pre-built Decisions Rules
Decisions comes with several pre-built Rules that handle common use case logic. For example, if two numbers need to be compared in a Flow, the pre-built Numbers Equal Rule would take number values as inputs and compare them against the Rule logic to determine if they are equal.
- Use a relevant naming convention to the Rule logic
It is recommended to use a naming convention on the Rule step that describes what the Rule is evaluating, as opposed to what the Rule is. In the screenshot below, "Admin Rule" is not as descriptive to the Designer user, but "Is user an admin?" provides more context about what the Rule checks.

Error Handling and Logging
- Understand Logging in Decisions
Decisions can be configured to record errors based on their log-level. Log steps can be placed on custom outcome paths or after certain steps in a Flow. This practice can help with troubleshooting issues in the product, but can sometimes cause overhead if the logging is excessive. It is recommended that ERROR and FATAL level logs are reserved for process or system errors respectively. Reference, Logging Overview.
- Understand Error Handling in Decisions
The Throw Exception step should only be used in a Flow that also contains a Catch Exception step, and this step should be used on exception outcome paths. These specific outcome paths can be configured in the step properties by enabling the "On Exception" path. Reference, System/Application Error Handling.
External Integrations
- Have failsafe logic for Flows relying on external API calls
When integrating external services and using these Flow steps in Decisions, it is recommended that failsafe logic is configured in case the API is unreachable or an error occurs. Flows can be designed to either continue and provide "missing" data or end in a failed state acceptably.
- Minimizing API calls can help with workflow application performance at runtime
- Cache API calls where possible
Caching API calls when appropriate can reduce the need for additional calls. For example, if an API needs an authentication token valid for 15 minutes on the first login, a Sub Flow can be created to get the authentication token and cache it for 14 minutes. In this case, no matter how many concurrent instances of the Flow are executed, the API authentication token is only requested once per 14 minutes.
Forms, User Interface
- The Grid layout makes Form component placement easier
Use Grid layouts (which is the default Form template layout) when creating a Form so that all of the Form components can fit easily and evenly in place. The Grid layout makes it easy to appropriately size rows and columns to create an organized interface. Other layouts like Canvas are beneficial in their freedom to place components anywhere, but they lack any automatic structural composition on the Form itself. Vertical/Horizontal Stack is excellent when using visibility Rules and trying to consolidate space, but they are limited in additional columns or rows. Reference, Form Layouts.
- Establish a Tab Order on Forms
Confirm that the "Tab Order" is configured appropriately so that when a user does a "tab" keystroke, the cursor will go to the next configured component on the Form in the order intended.
- Use a sequence of small Forms in a Flow as opposed to one large Form
The use of large Forms is not a best practice because if an error occurs, troubleshooting the error can be difficult when attempting to pinpoint which Form component is the error; a large Form may also become too complex and time-consuming when a user begins input and output mapping. Also, large Forms may slow down performance upon saving, especially if Visibility/Validation components are used. Users can break down large Forms into smaller Forms and call them into a sequence by using a Flow.
- Handling file data from upload/download components
When using File Upload/Download Form components to handle files, it is recommended that the FileReference data type is used for the data, as opposed to FileData.
- Use separate Data Flows for separate components
Data Flows should handle one Form component at a time. For example, it is not recommended to combine data return logic for two separate Form components together into one Flow. Reference, Using Data Flows.
Data Handling and Storage
- Handling objects of composite types
It is not recommended to nest objects of database stored composite types. For example, if new information is added to create an account, that new account would be an "object" of the [Account] data type. If one object is referenced in many locations, it is recommended that the object ID is stored in the table for all objects of the corresponding type.
- Saving Entity structures
With the Entity data structure (a data structure where records are visible in the User Portal and Designer Studio), the entities should be saved outside of the project folder structure so that they are not migrated into a Production environment.
- Plan which structures will be needed
For processes and applications that are intended to be used over a long period of time, it is good to prepare for this by planning the structure of the tables that will be used. For example, if data from a process needs to be stored temporarily over a six month time period, plan to add a column in the table with a date and create a Flow to delete those old records based on the date.
- Insert data, then update
In a use case where data needs to be both inserted and selectively updated, it is recommended that data is inserted first and then updated, as opposed to being inserted and updated at the same time.
Data Types
In Decisions, data structures are comprised of several data members that will hold values of a specified type. When the structure itself is created, all of these data members are compiled to create a new, composite data type. There are several different classifications of data structure in Decisions that function differently based on the type of data it is created to handle. For example, a Case Entity structure would be better for handling process data that goes through several states than a Database Structure would, since Case Entities have state-building aspects in the structure configuration itself. To that, a Database Structure would be much better for maintaining a software catalog list that might need to be changed frequently.
- Use consistent naming conventions
When maintaining several data types in a project, it is recommended that the same naming convention is used for clarity. By this, if camel casing is used, it should be consistent across all types in the project.
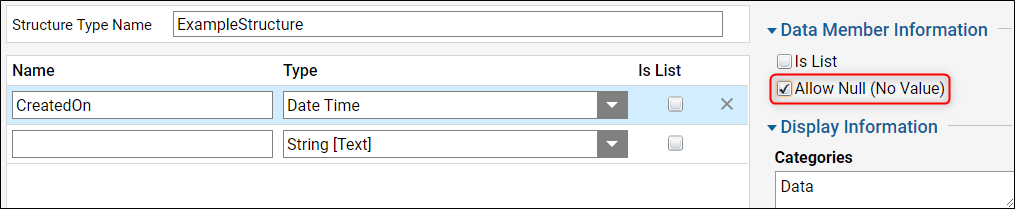
- Allow Null for DateTime data members that accept blank dates
If a data type is created with a data member that records a DateTime value and blank dates are allowed, then the data member will need to be enabled to allow null values in the Data Structure window.
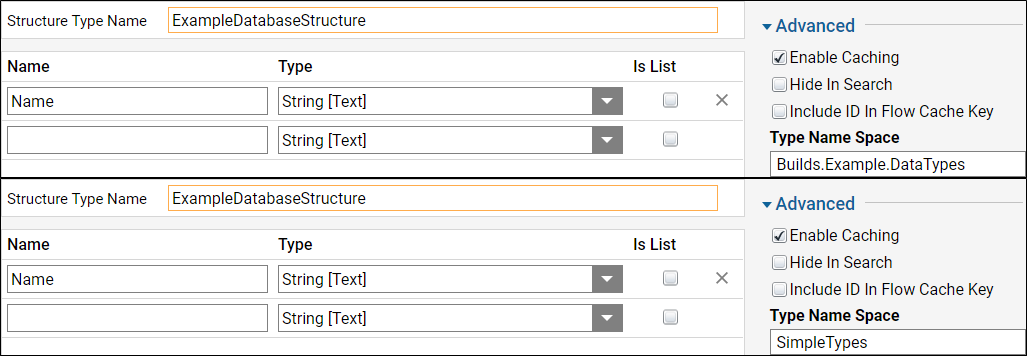
- Refrain from using the folder path as the Name Space on a structure
The Name Space section is used when generating the table name of the composite data type. This field defaults to the folder path where the type is being created, which is then used as the name of the table for this structure on the back-end database. Any structure created in this nested folder will appear with an extended table name in the database. This can also cause an issue if the data type were to be moved to another folder, as this does not change the table name where it is referenced.
In the screenshot below, the top window shows the Name Space pre-populated with where the new type will be located, so in the actual database table, the structure will appear as Builds.Example.DataTypes.ExampleDatabaseStructure. The bottom window shows a simplified Name Space related to this structure and/or the process/application it is part of. It will appear as SimpleTypes.ExampleDatabaseStructure.
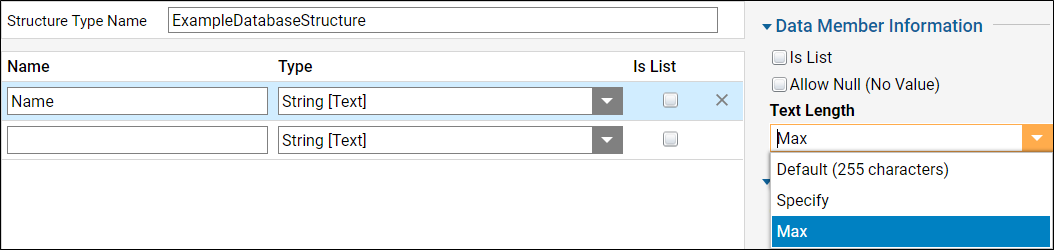
- Specify the Text Length of String data members
Set a maximum string length on data members that are expected to receive large strings of text. If this is not set, the text will be truncated to 254 characters.
- Use the Get All/Get By ID step of the user-defined type
Every data type that can be created in Decisions has steps created for it that perform a Get All or Get By ID action, which will either retrieve all of the objects of that type or just the object specified by ID.
Repository
The repository is a special type of Decisions server used for storing project resources and version control. The purpose of a repository is to help in storing projects and promoting changes between environments. Unlike a traditional Decisions server, a repository is not used for developing or running applications, it is simply used for storing and maintaining branches and versions of the project or application. Reference, Repository Overview.
- Know when to check a project into the repository
Typically projects are checked into the repository when development on a feature is complete, and that feature is ready to be promoted to a test environment. The development server is where builds from the repository that are ready to promote can be tested.
- Ensure the latest build revisions are accessible
An established routine method of checking in projects can make checking out a project with the latest updates much easier so that all of the dependency versions are up to date. When doing so, branching is a good way to create separate, compartmentalized sections of the repository for specific project save sessions.
- Confirm the project resources/dependencies
When checking in changes to the repository, by default Decisions will attempt to check in all resources for that project that has been modified since the last check-in. Decisions will show a checklist of all items with changes. Select or deselect as needed before confirming the check-in. The repository also offers the ability to only check in items that have been modified by the current user.
- Confirm where resources are deleted in the repository
One of the advantages of using a repository to manage deployments is that it provides the ability to delete resources from a project as part of a code migration. However, deleting a Flow from a project and deleting the resource from the repository are two different things. Checking in a project with a deleted resource will mark the resource as deleted in the repository. This is the recommended method for deleting items from a project in the repository. When checking out the project, the deleted item will be deleted from the server where the check out is happening. The resource remains in the repository as a part of the project in a deleted state.
- Implement project branches for maintainability
Repository branches are used to create a copy of a project at a snapshot in time. Each branch maintains a version of all the resources of the project independently. Unlike a normal development server that does not allow two versions of the same Flow, using branches can produce this behavior on the repository.
A server can only point to one branch for a project at a time. Using branches does not allow a production server to run two versions of the same Flow at one time.