Overview
When embarking on the development of applications and projects, it is crucial for users to prioritize functionality, reliability, and maintainability. By keeping these key aspects in mind throughout the development process, developers can significantly reduce errors and improve production time.
This article serves as a guide to best practices that users can follow. While adherence to these practices is not mandatory, they come highly recommended by Decisions developers as they contribute to efficient and effective development.
General Principles
| Practice | Purpose |
|---|
| Know the goal of the application being created | Understand the purpose and function of the overall build before starting development. It sets a solid foundation for the platform. |
| Record Project Documentation | Maintain up-to-date documentation on the application's intended function and testing plans throughout the development process. Keep track of changes made in the Designer Element and Folder. |
| Use consistent Folder Scaffolding | Organize items consistently across Projects, ensuring easy accessibility and findability. |
| Populate Info Panel of Designer Elements | Provide meaningful descriptions for Designer Elements that enable outsiders to understand their purpose effectively. |
| Frequently Save and Create Checkpoints | Regularly utilize the Save and Checkpoint actions to prevent the loss of progress during the design phase. |
| Test Build Logic Frequently | Test the data processing step by step during development to ensure data is in the right state throughout the runtime process. |
| Out of the Box Elements | Take advantage of Decisions' pre-built Rules and Flows that fulfill common business logic needs. Avoid modifying these elements to maintain compatibility with other processes. |
| Contact Decisions Support | Reach out to Decisions Support at support@decisions.com if any issues are encountered beyond your understanding of the environment. |
Technical Practices
| Practice | Purpose |
|---|
| Understand Logging | Decisions can be configured to record errors based on their log level. Log steps can be placed on custom outcome paths or after specific steps in a Flow. This practice helps in troubleshooting issues, but excessive logging can cause overhead. Reserve ERROR and FATAL level logs for process or system errors.
It is recommended to establish a consistent naming strategy for log categories, such as starting with "Debugging" followed by the project name, e.g., "Debugging-AccountEventListener" or "Debugging-LockBoxProcessor." |
| Understand Error Handling | The Throw Exception step should only be used within a Flow that includes a Catch Exception step. Configure the Catch Exception step to handle exception outcome paths. This can be done by enabling the "On Exception" path in the step properties. |
Flow Design
| Practice | Purpose |
|---|
| Reference Composite Types Early in the Flow | Call Data Structures into the Flow as early as possible so that the Change Value output mapping can directly output data from a step as a value of the specified structure. |
| Design Flow Step Layout with easy maintainability | Flow readability is crucial when designing Flow logic. The recommended Flow layout involves orchestrating steps from left to right, top to bottom. Lines should be as straight as possible. Additionally, rename steps to reflect their specific purpose in the Flow. Connect steps and arrows to the processing logic in functional sequence while viewing it from the Designer's view. | 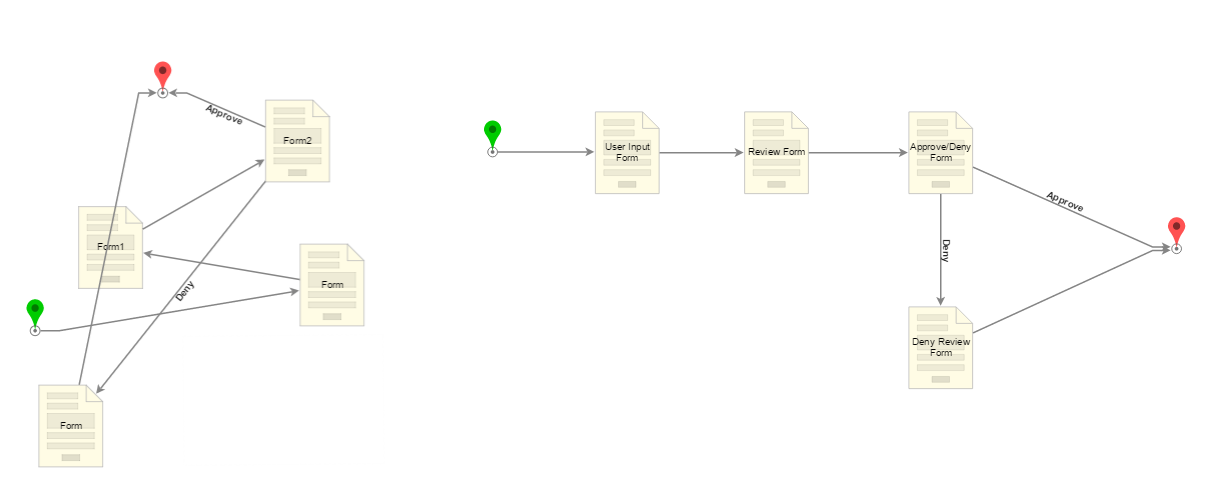 |
| Annotation Steps | Utilize annotation steps to provide summaries at important moments in a Flow. |
|
| Use the Most Efficient Steps/Paradigms | Optimize the Flow by using the most efficient steps and paradigms. Avoid using multiple steps when one can accomplish the task. Utilize Truth Tables instead of multiple sequential rules. Replace the combination of For Each step and Rules with the Collection Filter step for list filtering. Filter Fetch Entities to return only the desired data when possible.
Use default Converter Flows instead of their separate steps. Prefer using out-of-the-box Steps or Rules instead of creating custom ones unless they are reused, have business significance, or involve multiple conditions. If only a True/False output is required from a Rule, uncheck "Expose Step as a Rule" from the Outcome section and use the output as a variable (excluding routing scenarios). |
| Use Access Patterns | Create access patterns when needing to input data with the same criteria in multiple places within the Project. This helps save time in configuring fetch steps. |
|
| Reusing Logic with Sub Flows | For maintainability, use fewer steps to build logic and compartmentalize specific process steps into Sub Flows. Reference Sub Flows from other Flows using the Run Sub Flow Step, which populates the step with values from the sourced Flow. After creating a Flow, select multiple steps to create a Sub Flow directly within a Parent Flow. |
| Data is being transferred through Sub Flows efficiently | Consider the functionality, keep variable names consistent, and maintain a clean Data Explorer. Pass entire objects when necessary rather than individual fields. Use the Change Value step instead of declaring multiple new data types to pass in and out of flows. |
| Practice Development Refinement | Create Templates for commonly used components to reduce development time. |
| Appropriate Naming Conventions Used | Use clear names that provide insight into the function of the Flow/step and the associated project. Use tagging to include helpful metadata for the designer element. When using collections, rename single items to indicate they are part of an object and name collections to indicate their contents. |
| Exception Handling | Avoid Email steps in exception handling logic unless they also have exception handling. Ensure that exception-handling sub-flows are asynchronous if they contain an assignment unless the Flow should pause. The exception message should be intuitive and should not contain personally identifiable information (PII) or payment card industry (PCI) data. Appropriately name and categorize the Logging step. |
| Unit Tests are utilized | Utilize Unit Tests to test different scenarios in the Flow. |
Looping/Lists
| Practice | Purpose |
|---|
| Exercise caution regarding recursion limits when using looping. | By default, Flows have a recursion limit of 20,000 to prevent infinite loops that consume system resources. Although it is possible to modify this limit within the Flow Designer, setting high or unlimited recursion limits can lead to performance issues. For example, if a Flow has a recursion limit of 20,000 and calls a sub-flow that loops 30,000 times, it will throw an exception in the environment. |
| Utilize ForEach looping when there is a dependency on the data processing order or the ForEachBreak step. | In scenarios where another list of items needs to be fetched before the completion of the first list's looping, the ForEach Break step should be employed to reset the internal counter of the ForEach step. Otherwise, the ForEach step will resume from the last received row number. This approach ensures proper handling of dependencies and maintains the desired order of data processing. |
| Implement parallel processing with the Run Flow For List [Batch Processing] step. | To enable parallel processing, the Run Flow For List [Batch Processing] step should be used. This Step spawns asynchronous processing threads, making it suitable for scenarios where independent processing can occur simultaneously. If the processing threads have substantial workloads and the parent Flow relies on their completion, the parent Flow may need to pause processing or restrict the retrieval of processed data until a reasonable time. This Step ensures that the parent flow proceeds only after all independent processing threads have been spawned rather than waiting for their completion. |
| Handle CSV iterations with no dependencies. | When iterating through a CSV file without dependencies, an alternative approach is to bypass the "For Each Row in CSV" step and perform bulk processing of all rows at once using the "Run Flow for CSV" component. However, it is important to note that this approach may encounter failures when dealing with large data sets containing 300,000 or more rows. |
Rules
| Practice | Purpose |
|---|
| Utilize the pre-built Decisions Rules | Decisions provides a variety of pre-built Rules designed to handle common use case scenarios. One such example is the Numbers Equal Rule, which is specifically designed to compare two numbers within a Flow. By taking number values as inputs and evaluating them against the Rule logic, the Numbers Equal Rule determines whether the two numbers are equal or not. |
| Use a relevant naming convention to the Rule logic | To enhance clarity for the Designer user, it is advisable to employ a naming convention for Rule steps that describes the evaluation performed by the Rule rather than simply stating the Rule itself. In the provided screenshot, using a more descriptive name such as "Is the user an admin?" instead of "Admin Rule" provides additional context and aids in understanding the purpose and functionality of the Rule. | 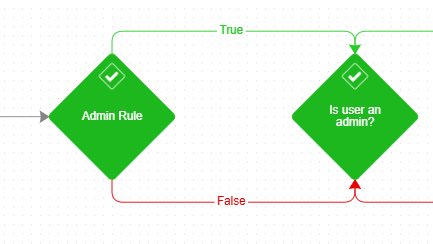
|
External Integrations
| Practice | Purpose |
|---|
| Have failsafe logic for Flows relying on external API calls | When integrating external services and using these Flow steps, it is recommended that failsafe logic is configured in case the API is unreachable or an error occurs. Flows can be designed to either continue and provide "missing" data or end in a failed state acceptably. |
| Minimize API calls | Minimizing API calls can help with workflow performance at runtime. |
| Cache API calls where possible | Caching API calls when appropriate can reduce the need for additional calls. For example, if an API needs an authentication token valid for 15 minutes on the first login, a Sub Flow can be created to get and cache it for 14 minutes. In this case, no matter how many concurrent instances of the Flow are executed, the API authentication token is only requested once per 14 minutes. |
| Database Calls are done efficiently (writes, reads, etc.) | If an entire object is in a Parent Flow, pass it into the Child Flow. If not, pass the id and fetch the object in the child Flow. |
Forms
| Practice | Purpose |
|---|
| The Grid layout makes Form Control placement easier | Use Grid layouts when creating a Form so that all of the Form controls can fit easily and evenly in place. The Grid layout makes it easy to size rows and columns to create an organized interface appropriately.
Other layouts like Canvas are beneficial for their lack of placement constraints, but because of that, they lack automatic structure. Vertical/Horizontal Stack is excellent when using visibility Rules and trying to consolidate space, but they are limited in additional columns or rows. |
| Establish a Tab Order on Forms | Confirm that the "Tab Order" is configured appropriately so that when a user does a "tab" keystroke, the cursor will go to the next configured control on the Form in the order intended. |
| Handling file data from upload/download controls | When using File Upload/Download Form controls to handle files, it is recommended that the FileReference data type is used for the data instead of FileData. |
| Use a sequence of small Forms in a Flow instead of one large Form | Using large Forms is not a best practice because if an error occurs, troubleshooting the error can be difficult when attempting to pinpoint which Form controls is the error; a large Form may also become too complex and time-consuming when a user begins to input and output mapping. Large Forms may slow down performance upon saving, especially if Visibility/Validation controls are used. Users can break down large Forms into smaller Forms and call them into a sequence using a Flow. |
| End Forms are Used Effectively | End Forms confirm that the user's action was successful. Signals the end of user interaction in a Flow. |
| UI Should be Designed Consistently | Always add Form titles and Report titles. |
Data Handling and Storage
| Practice | Purpose |
|---|
| Handling objects of composite types | It is not recommended to nest objects of database-stored composite types. For example, if new information is added to create an account, that new account would be an Object [Account] data type. If one Object is referenced in many locations, it is recommended that the object ID is stored in the table for all objects of the corresponding type. |
| Saving Entity structures | With the Entity Data Structure, which keeps records visible in the Portal and Studio, the Entities should be saved outside the project folder structure so they are not migrated into a production environment. |
| Plan which structures will be needed | For processes and applications that are intended to be used over a long period of time, it is good to prepare for this by planning the structure of the tables that will be used. For example, if data from a process needs to be stored temporarily over a six-month time period, plan to add a column in the table with a date and create a Flow to delete those old records based on the date. |
| Insert data, then update | In a use case where data needs to be inserted and selectively updated, it is recommended that data is inserted first and then updated instead of being inserted and updated simultaneously. |
| Handling sensitive values for data | For increased security in handling data, data structures that record to the database can mark properties as containing Personally Identifiable Information (PII). |
| Limit Query Results | Limit query results by using the "Limit Count" input on the query step or constructing queries that return limited subsets of the data in chunks for processing. If all data is to be processed, dealing with the smallest logical unit is the best practice. |
Data Types
| Practice | Purpose |
|---|
| Understand which Data Structure to use for the Data Being Handled | Data Structures comprise several data members holding values of a specified type. When the structure is created, all these data members are compiled to create a new composite data type. Different classifications of Data Structure function differently based on the type of data it is created to handle.
For example, a Case Entity structure would be better for handling process data that goes through several states than a Database Structure since it has state-building aspects in the structure configuration itself. A Database Structure would be much better for maintaining a software catalog list that might need to be changed frequently. |
| Use consistent naming conventions. | When maintaining several data types in a project, it is recommended that the same naming convention is used for clarity. If camel casing is used, it should be consistent across all types in the project. |
| Allow Null for DateTime data members that accept blank dates | If a data type is created with a data member that records a DateTime value and blank dates are allowed, then the data member must be enabled to allow null values in the Data Structure window. If this is not set, empty dates will be set to 1/1/1753 in the database and Reports. | 
|
| Set the Namespace on Data Types | The Namespace section is used when generating the table name of the composite data type. This field defaults to the folder path where the type is being created, which is then used as the table name for this structure on the back-end database. Any structure created in this nested folder will appear with an extended table name in the database. This can also cause an issue if the data type were moved to another folder, as this does not change the table name where it is referenced.
In the screenshot, the top window shows the Name Space pre-populated with where the new type will be located, so in the actual database table, the structure will appear as Builds.Example.DataTypes.ExampleStructure. The bottom window shows a simplified Name Space related to this structure and/or the process/application it is part of. It will appear as SampleTypes.ExampleStructure. | 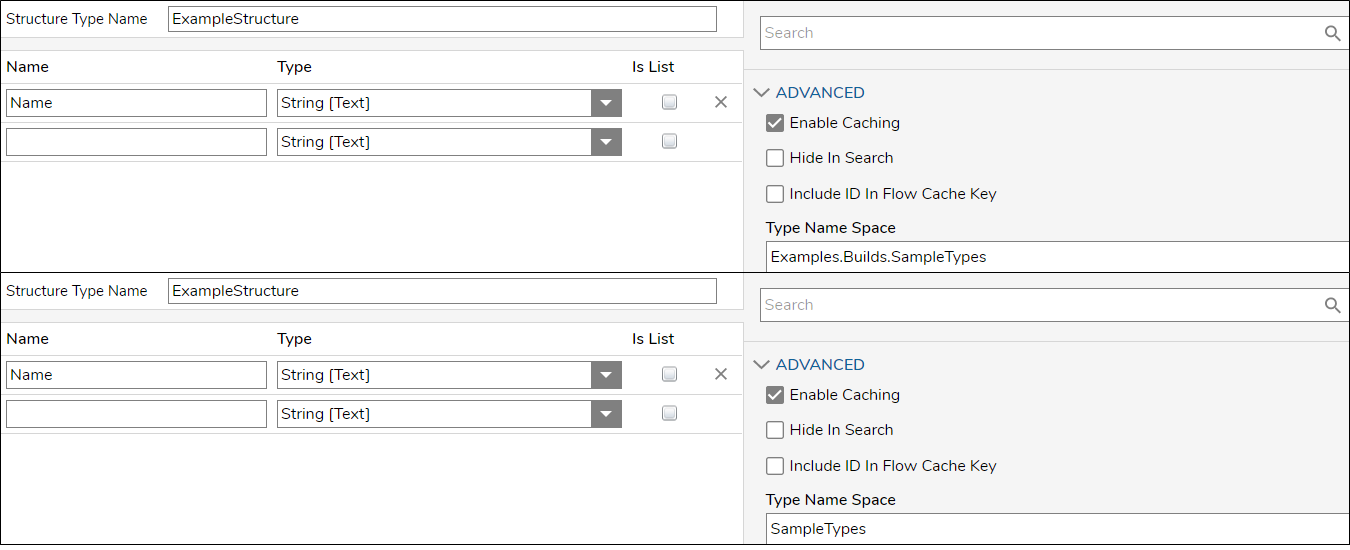 |
| Specify the Text Length of String Data Members | Set a maximum string length on data members expected to receive large text strings. The text will be truncated to 254 characters if this is not set. | 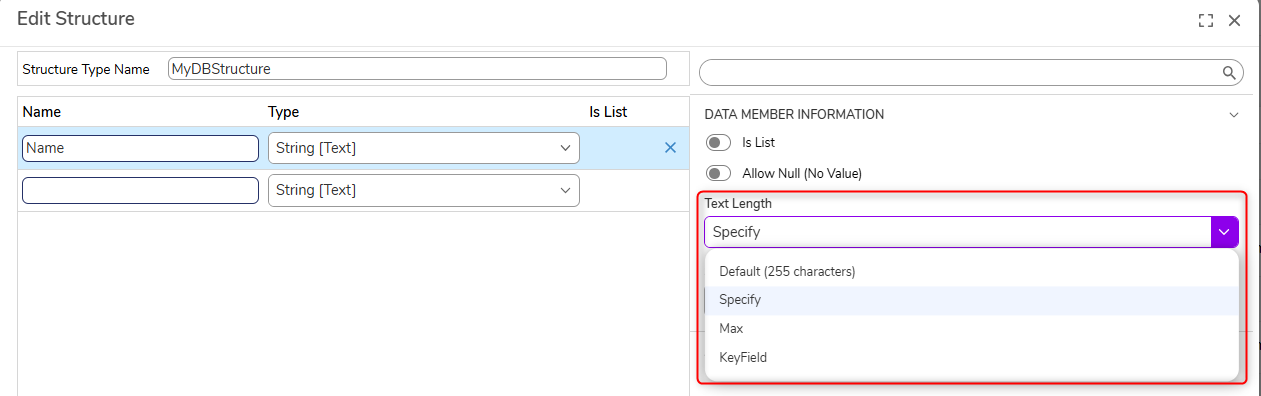
|
| Use the Get All/Get By ID step of the user-defined type | Every data type that can be created in Decisions has steps that perform a Get All or Get By ID action, which will either retrieve all of the objects of that type or just the object specified by ID. |
| Practice | Purpose |
|---|
| Know when to check a project into the repository | Typically Projects are checked into the repository when development on a feature is complete and that feature is ready to be promoted to a test environment. |
| Ensure the latest build revisions are accessible | An established routine method of checking in projects can make checking out a project with the latest updates much easier so that all dependency versions are up to date. Branching is a good way to create separate, compartmentalized repository sections for specific project save sessions. |
| Confirm the Project resources/dependencies | When checking in changes to the repository, by default, Decisions will attempt to check in all resources for that Project that has been modified since the last check-in. Decisions will show a checklist of all items with changes. Select or deselect as needed before confirming the check-in. The repository also offers the ability only to check items that have been modified by the current user. |
| Confirm where resources are deleted in the repository | One of the advantages of using a repository to manage deployments is that it allows the deletion of resources from a Project as part of a code migration. However, deleting a Flow from a Project and deleting the resource from the repository are two different things. Checking in a Project with a deleted resource will mark the resource as deleted in the repository. This is the recommended method for deleting items from a Project in the repository. When checking out the Project, the deleted item will be deleted from the server where the checkout is happening. The resource remains in the repository as a part of the Project in a deleted state. |
| Implement project branches for maintainability | Repository branches are used to create a copy of a project at a snapshot in time. Each branch maintains a version of all the resources of the Project independently. Unlike a normal development server that does not allow two versions of the same Flow, using branches can produce this behavior on the repository.
A server can only point to one branch for a project. Using branches does not allow a production server to run simultaneously two versions of the same Flow. |