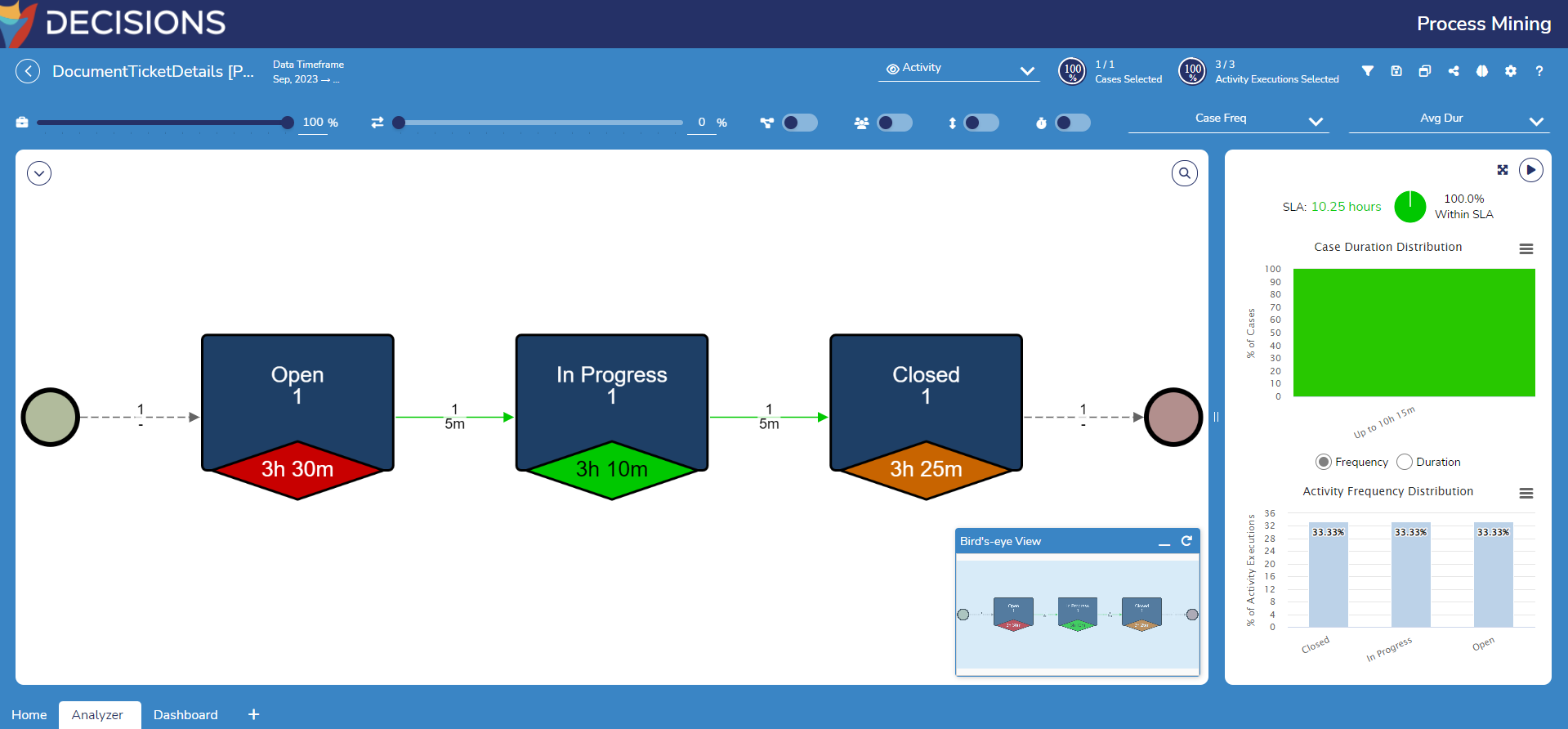
Overview
Currently, Process Mining can connect to and access data generated from Decisions, Jira, Salesforce, and ServiceNow. The Process Mining Flow Structure feature within Decisions enables Users to gather data from external services integrated with Decisions and seamlessly transfer it to the Process Mining Platform as an Event log. This feature significantly enhances data integration and analysis in Process Mining, making it more compatible with Decision Services.
How does the Process Mining Flow Structure work?
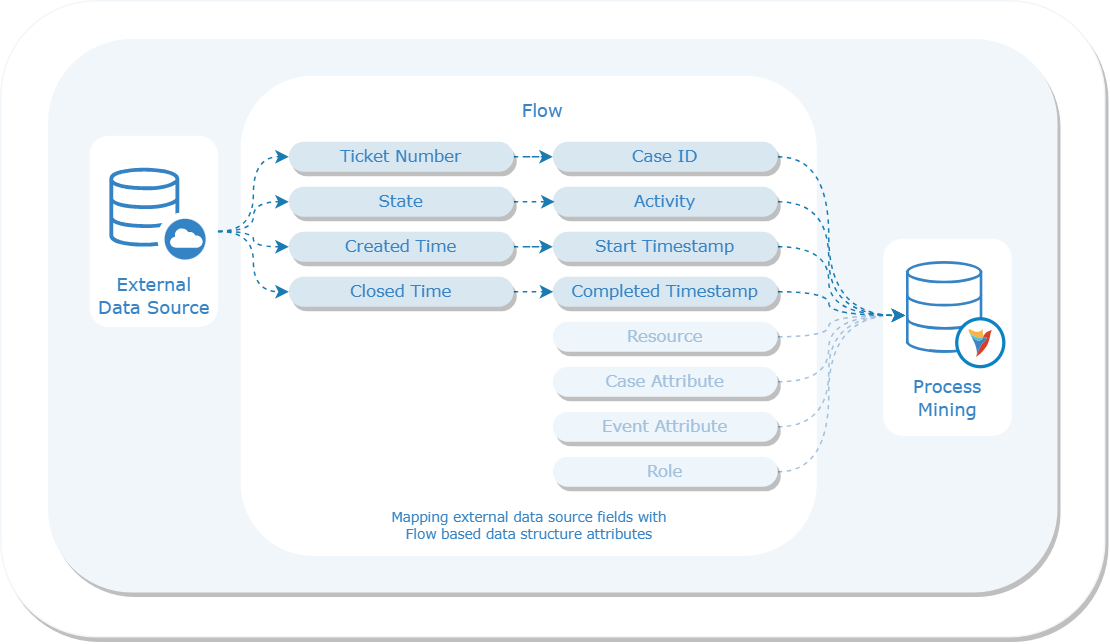
External data cannot be directly input into Process Mining as it operates with its specific data structure based on the following attributes:
- Case ID
- Activity
- Completed Timestamp
- Start Timestamp
- Resource
- Role
- Case Attributes
- Event Attributes
It is crucial to ensure that mapping of any external data or data generated within Decisions to these attributes is enabled, allowing for effective interpretation and analysis by Process Mining.
To achieve this mapping, Users must create a Process Mining Flow Structure. It is a type of User-Defined Data Structure that allows Users to generate data fields and associated Datatypes to map with Process Mining attributes. These structures are utilized to standardize data. Each instance of this structure represents a single event and must include the following fields:
- Case ID: A unique identifier shared across all Events belonging to the same case. It links events together into a Process Instance.
- Activity: The name of the performed task.
- Completed Timestamp: A timestamp indicating when the task started. This enables calculation of task durations.
Optionally, Users can also include:
- StartTimestamp: A timestamp indicating when the task started. This enables calculation of task durations.
Attribute Mapping
Each attribute in the Process Mining Flow Structure must be mapped to a role in the Process Mining Platform:
- The required fields (CaseId, Activity, CompletedTimestamp) already have predefined roles.
- For additional fields, Users must assign each role when defining the structure. For example:
- A StartTimestamp field can be mapped to the Start Timestamp role.
- Resource and Role fields can be mapped to their respective roles, which are especially valuable for analyzing performance by resource (e.g., Mary) or role (e.g, Clerk)
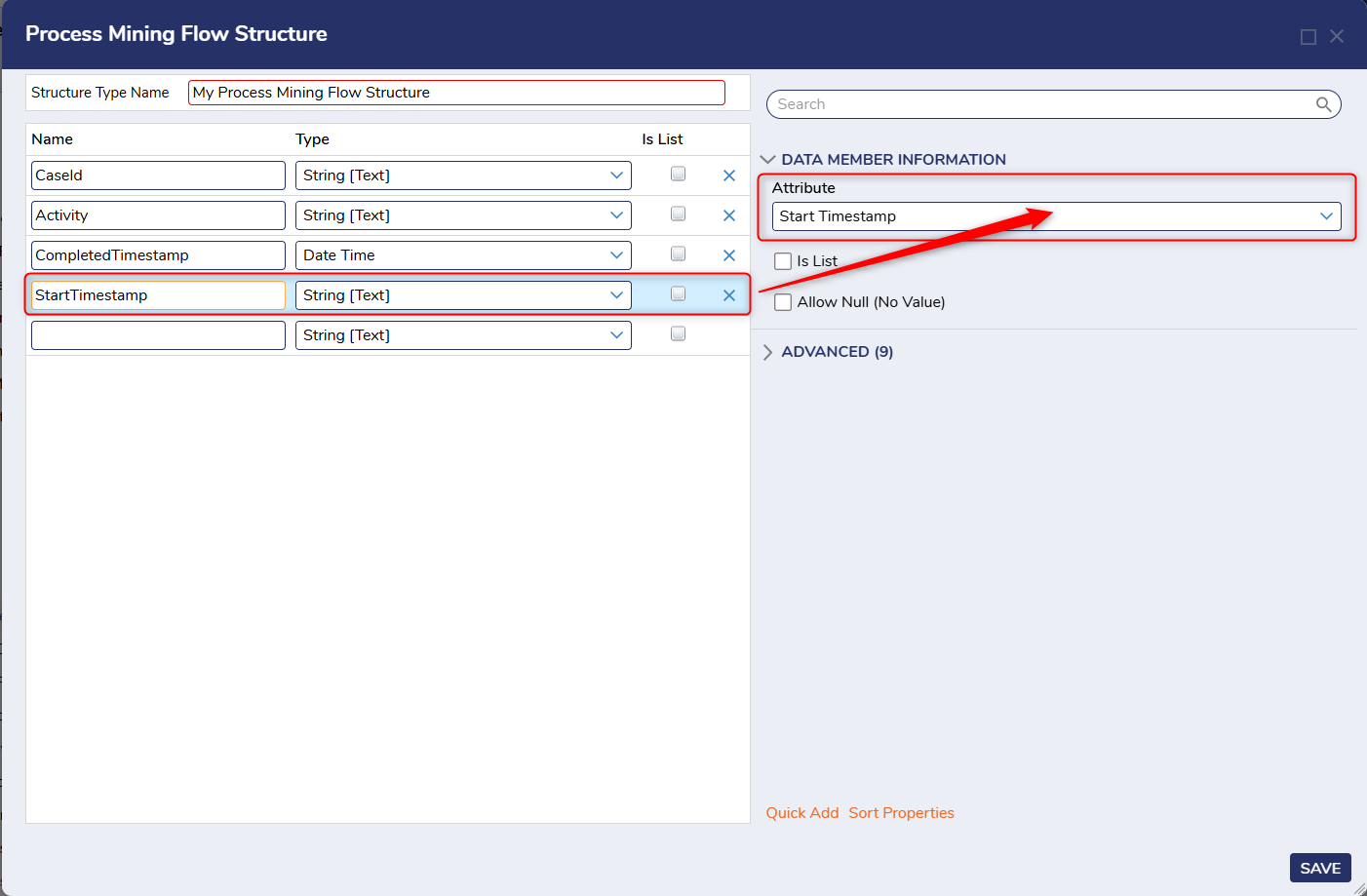
- Case Attributes: Properties of the entire case that remain constant throughout its lifecycle (e.g., order ID, loan amount, product category)
- Event Attributes: Properties of a single activity execution that may vary across events within the same vase (e.g., activity name, start/end time, resource, role).
When adding extra fields to the Flow Structure, it is recommended to enable Allow Null. This prevents the import process from failing if some events do not contain values for those fields. For example, when defining a StartTimestamp field in addition to the required CompletedTimestamp, Users should allow null for whichever field may not always be populated. However, at least one of these timestamps must be non-null; otherwise, the Event should be discarded.
Data Import Process
Once this Process Mining Flow Structure is saved, it will generate a Flow. Users will have to edit this Flow to fetch and convert raw data into an array of events that conform to this structure. Below are general steps that explain the Data Import Process.
The Process Mining Flow receives two inputs: StartTimestamp and EndTimestamp, which define a timeframe window. These steps must be completed to begin the data import process:
- Retrieve all events from the data that start and/or completion timestamps fall within this timeframe.
- For each retrieved event, create an instance of the defined Flow Structure (Process Mining Event) and map each of the retrieved event's data fields to the attributes of the Flow Structure. This will create a Process Mining standardized event.
- Add each created Process Mining event to a list.
- Once all Process Mining Events are added to the list, sort the list by the CaseID Field.
- Use the list as the Flow Output.
Note: Users will not be able to build Input data within the Flow using SETUP INPUT DATA. The output type of the generated Flow will consist of a list of Process Mining Flow Data structures, and it cannot be modified.
The next section will walk through the above-mentioned steps with a working example to further demonstrate the process.
Configuration
The following section demonstrates how to generate a Process Mining Flow Structure, map it with Process Mining attributes, and import the Flow Structure into Process Mining.
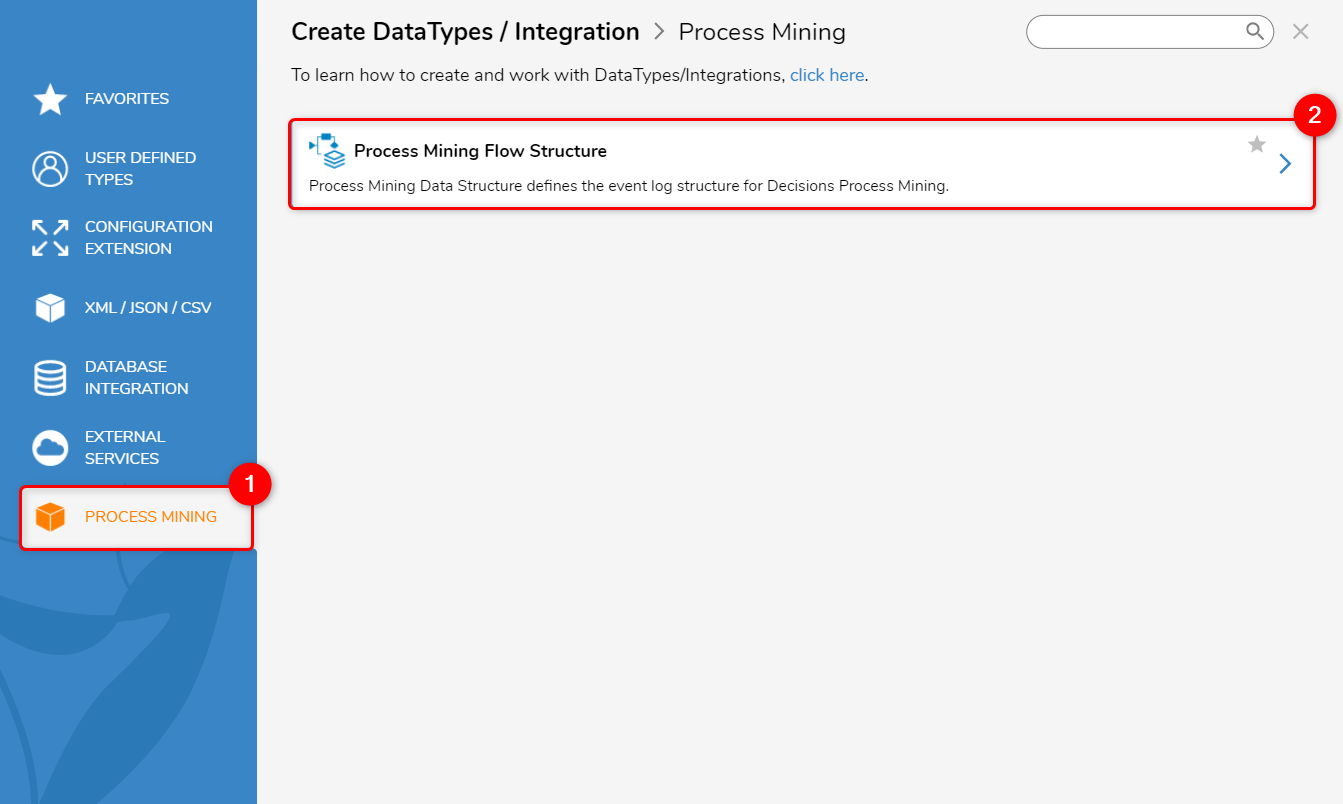
- In a Project, select CREATE DATATYPES/INTEGRATION from the Global Action Bar.
- From the Create DataTypes/Integration window, select Process Mining, located at the bottom-left.
- Click on the Process Mining Flow Structure.
- Declare a Structure Type Name (Document Ticket Details). Declare the data fields by inputting a Name and selecting a Type.
- To associate each data field with its corresponding Process Mining Attribute, go to the DATA MEMBER INFORMATION section and select the desired Attribute from the provided drop-down menu.
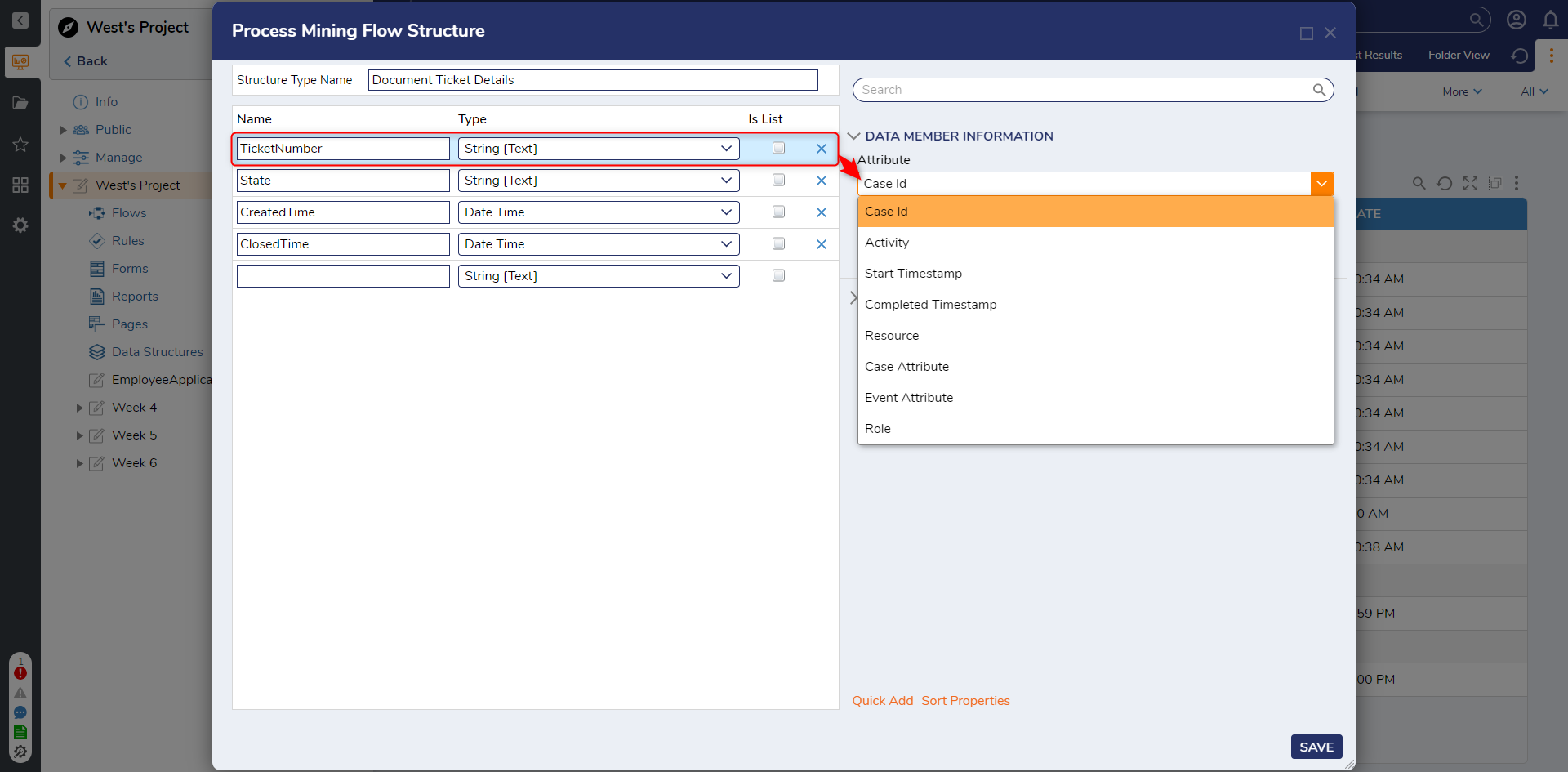
- Click on Save.
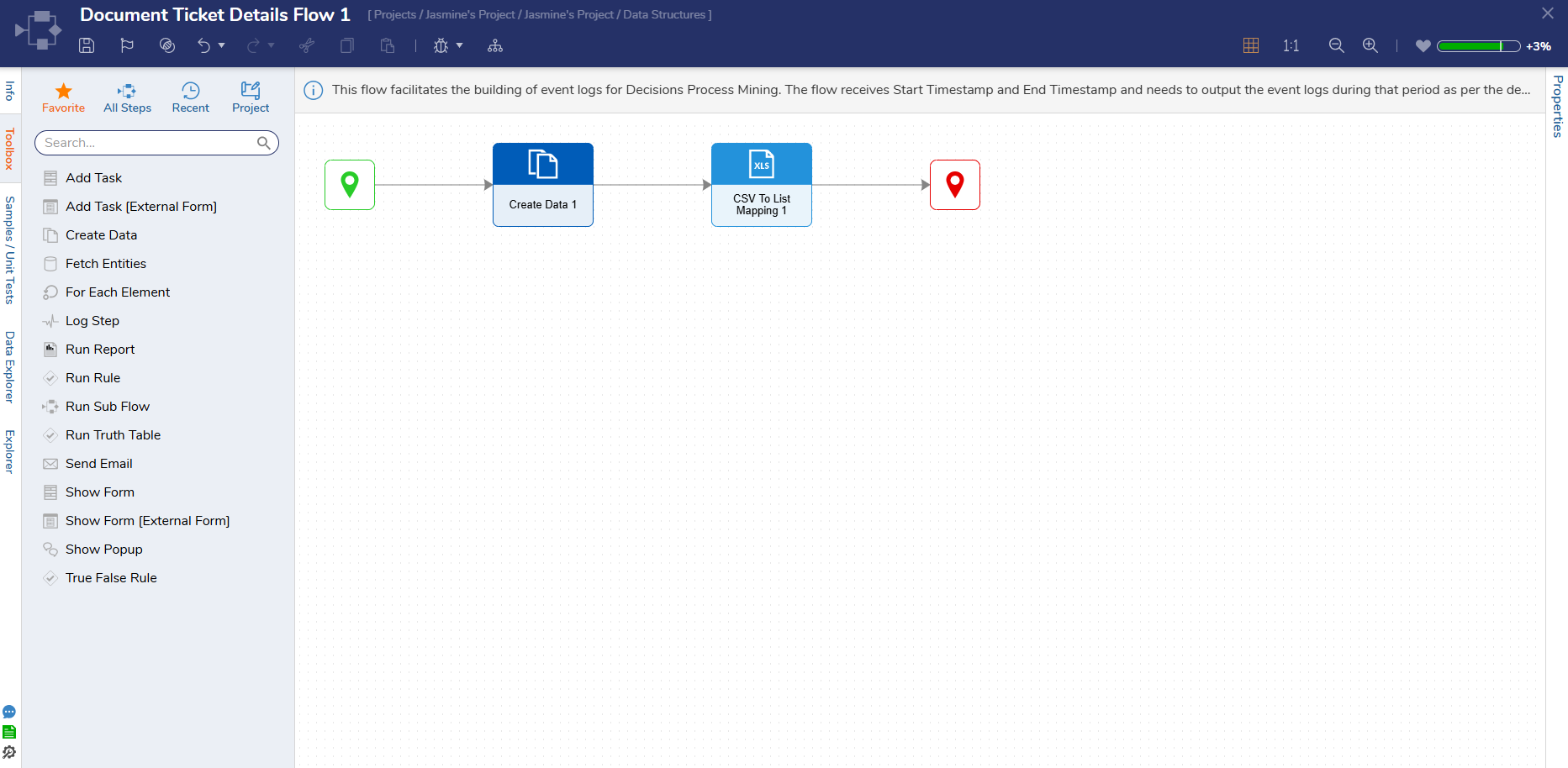
- Once the Process Mining Flow Data Structure has been created, it will generate the Process Mining Behavior Flow. To edit the Flow, right-click on Process Mining Flow Data Structure and select "Edit Flow".
- Next, configure the Flow to retrieve data from the desired source, such as a CSV file, JSONdata, or any other suitable data source.
- Note: Users can edit the Process Mining Flow to include data clean-up functionality.
- In the following example, a Create Data Step is used to import a CSV file. Then, a CSV to List Mapping Step is used to map it with the data fields of the Process Mining Data Structure and pass it to the output.
- Navigate to Process Mining. From the top action bar, click on Import/Export > Connect. From the Data Connectors window, click on Decisions.
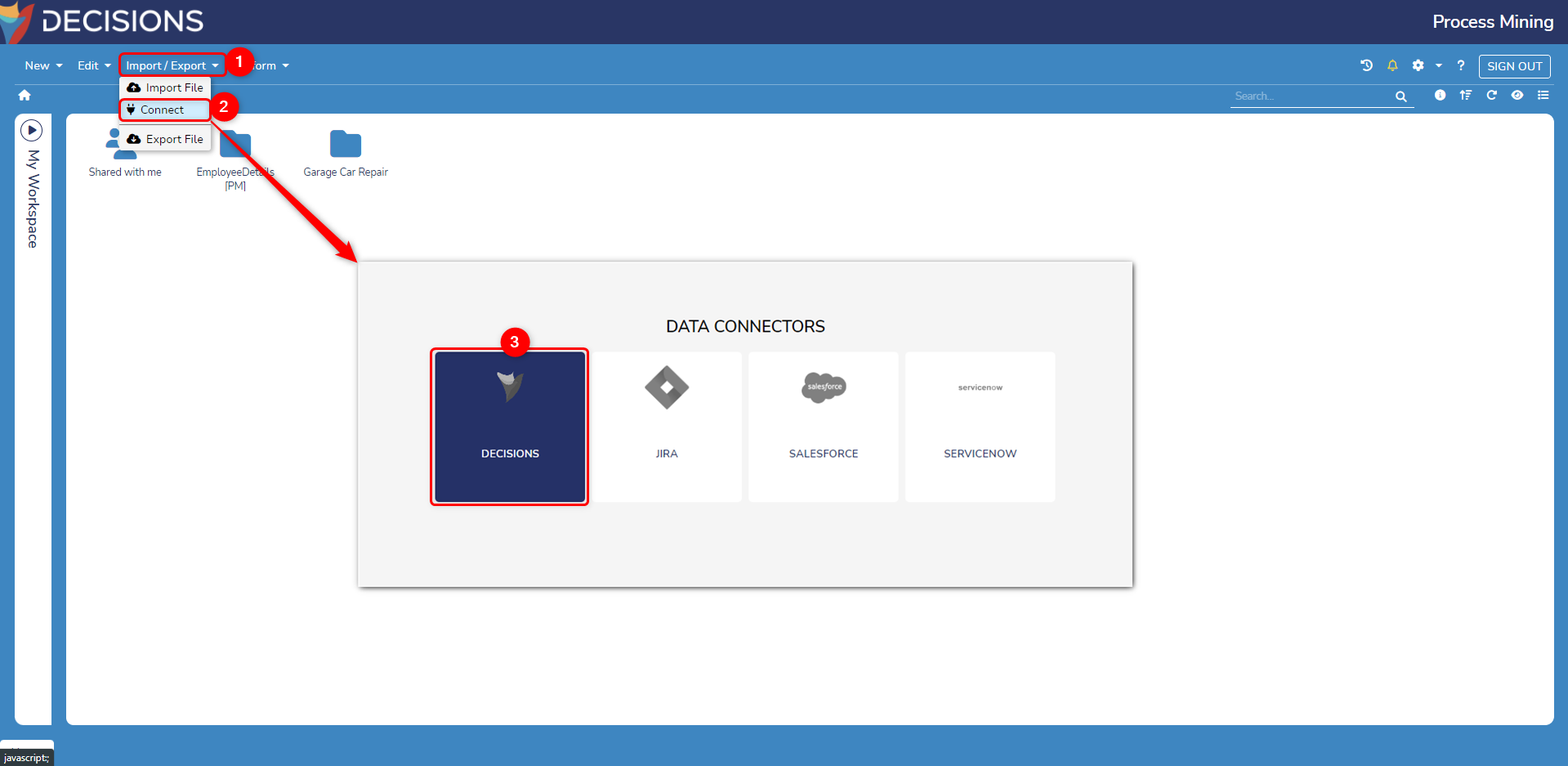
- The Decisions Data Connector displays all connected Data Structures with the Decisions instance. Enable the desired Process Mining Flow data structure and provide a desired start date to fetch the data.
Note: Importing Data Structures might take a few minutes. The platform will notify Users through a notification once the import is completed. If there are any issues with the imported Data, a warning will be displayed.
Execution in the Process Mining Platform
The following steps describe how an import is executed in the Process Mining Platform:
- The Platform calls the selected Process Mining Flow, providing a timeframe window.
- The Flow fetched all relevant events, maps them to a structure, and returns them as an output.
- The Platform stores the returned events in the Event Log.
- The Platform then requests the next timeframe, repeating the process until all data is imported.
- Once the import is completed, it will add a Folder to the dashboard. Open the folder and double-click on the Event Log file to open the process.