Feature Deprecated
Overview
| Data Structure Quick Summary | ||||||
|---|---|---|---|---|---|---|
| Complexity? | Performance Impact? | Saves to Database? | Configuration Folder? | Entity Framework? | Folder Behavior? | Process Tracking? |
| High | High | Yes | Yes | Yes | Yes | Yes |
The Flow Execution Extension is used for tracking linear processes. The Flow Execution Extension comes with out-of-the-box steps that are automatically aware of data being used in a Flow.
Example
- In a Designer Project, click CREATE DATATYPES/INTEGRATION and click Flow Execution Extension.
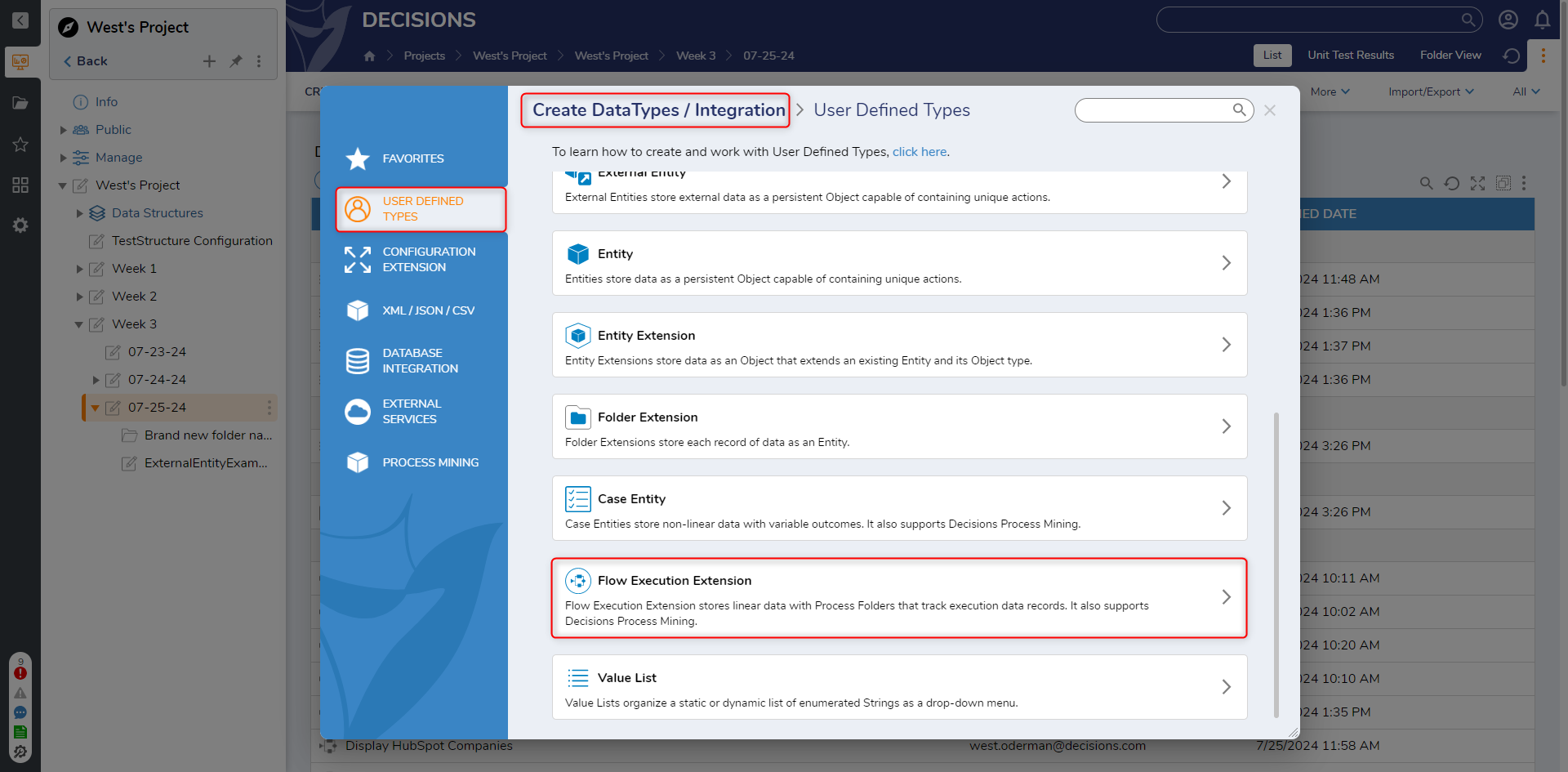
- In the Flow Execution Extension dialog window, enter a name for the Flow Execution Extension in the Structure Type Name field. Define data members and the data types. Click SAVE.
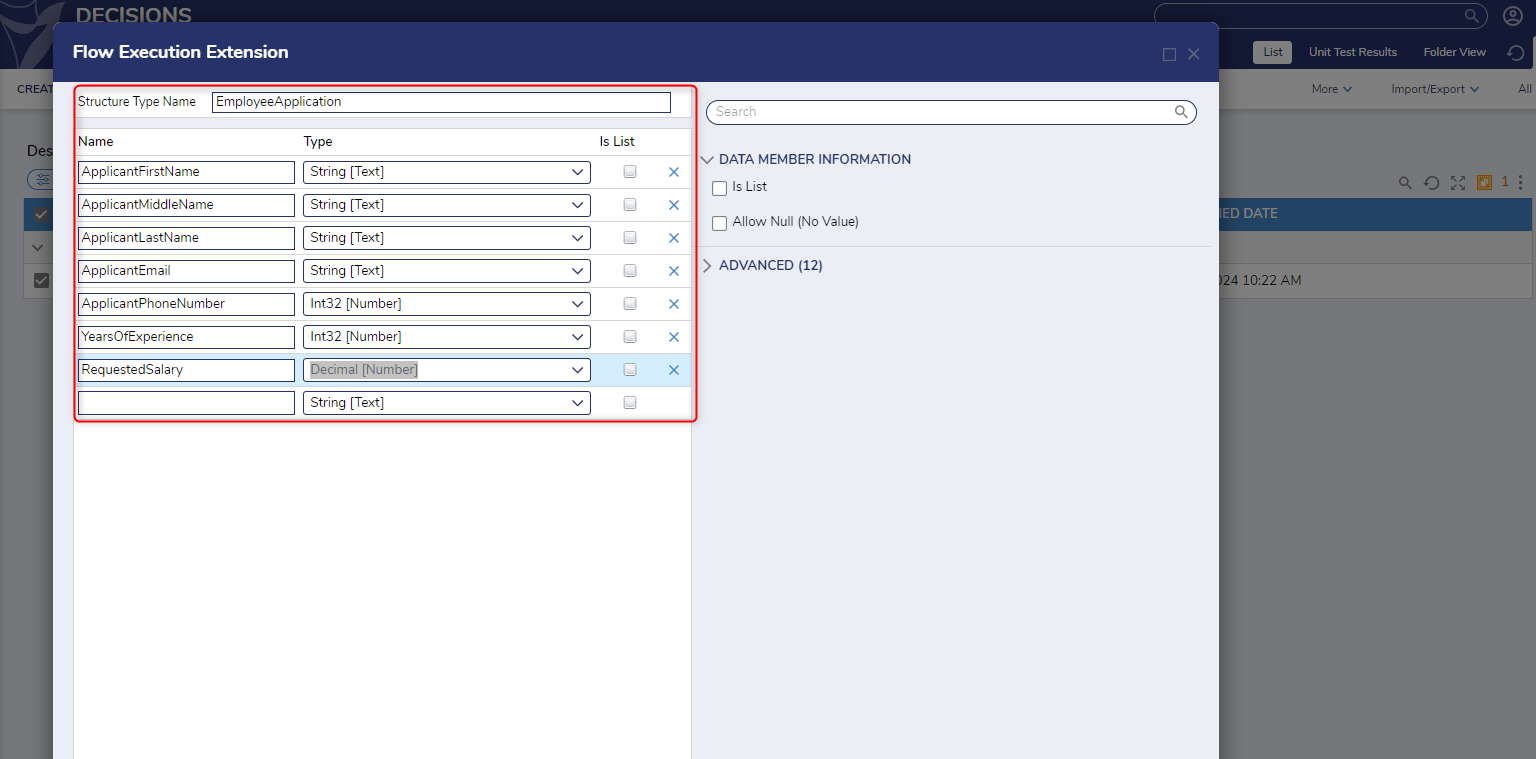
Flow Execution Extension Data Structure Settings
| Setting Name | Description |
|---|---|
| Enable Caching | Enables the Entity to be loaded into the cache |
| Enable Process Mining | Enables the Data Structure to be used with Process Mining |
| Hide In Search | This hides the data type from appearing when it is searched |
| Include ID In Flow Cache Key | Adds the GUID to the Cache Step Key for easier searching |
| Type Name Space | Creates the unique identifier for the Entity (namespace.typename) and is used to generate the SQL table name for the Entity (namespace_typename) |
| Audit Changes | This saves changes to entity data in the Audited Entities table. This option is used when data monitoring is required for this Entity |
| Category Order | Allows data field categories to be organized in a certain way. For example, grouping required data fields together |
| Include Type Name In Description | This enables or disables the visibility of the Type namespace |
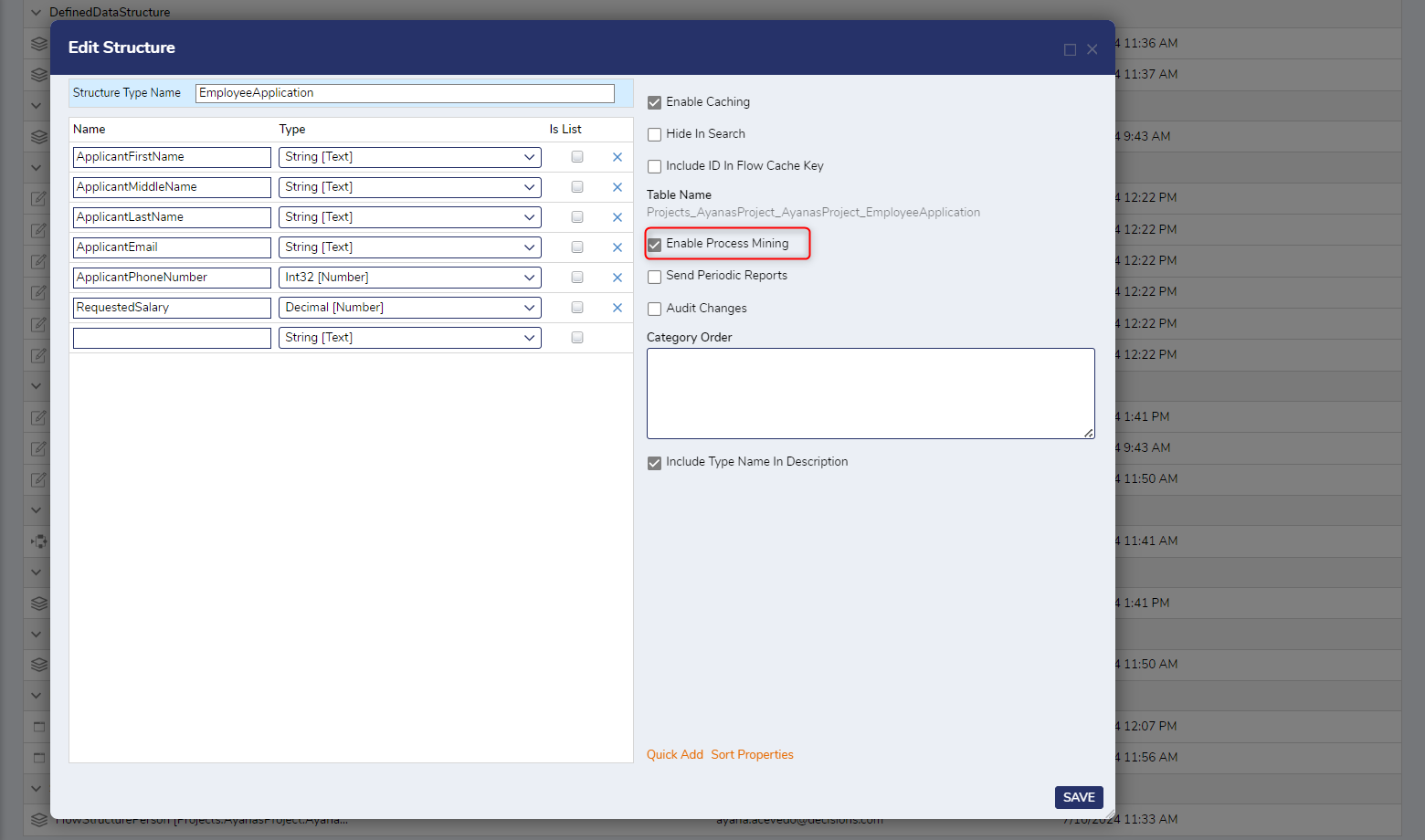
Enabling Process Mining
To allow data within the Case Entity to be used in process mining, enabled the Enable Process Mining setting in the Flow Execution Extension creation dialog under the Advanced section.
Ensure there are data fields within the Flow Execution Extension that fulfill the data variable requirements for process mining.
Creating Records via Process Folders
The Setup Process Folder step creates save-able records for the Flow Execution Extension. It is best practice to place the steps after the Setup Process Folder step to avoid errors.
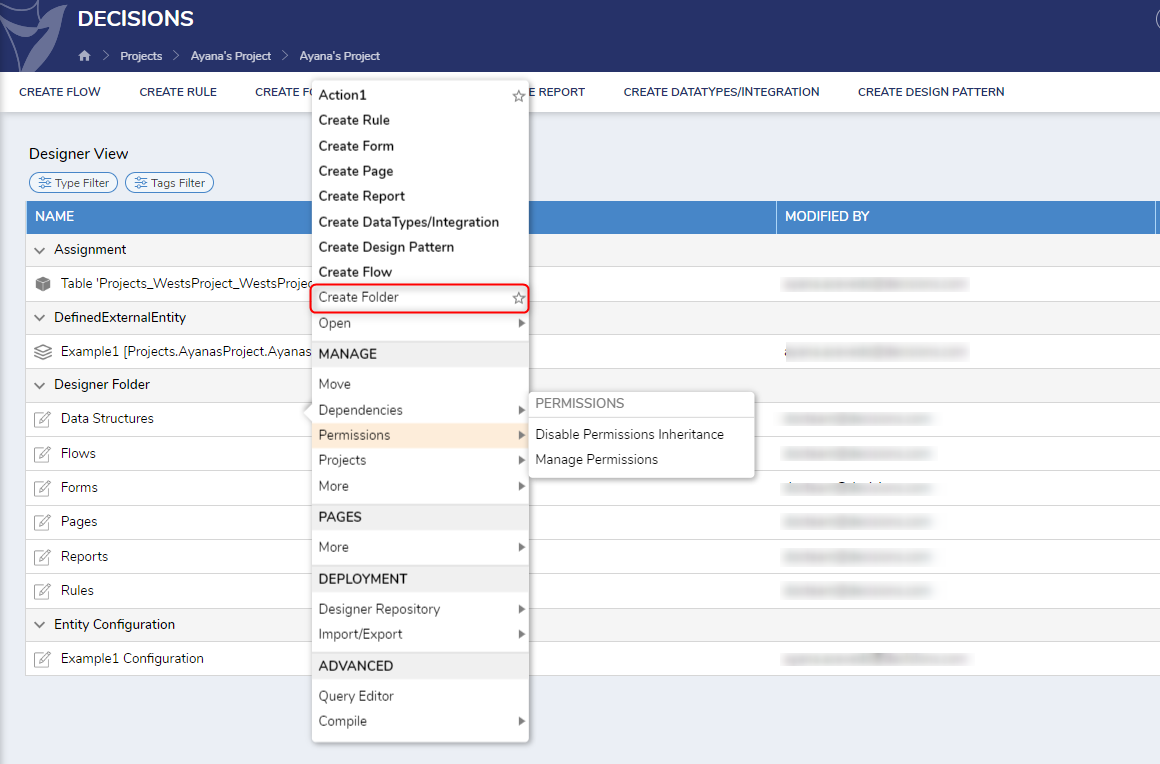
- Right click on a Designer Folder and select the Create Folder action to create a Folder. Name it 'ExampleFEEData' and select CREATE to confirm. It will now appear in the Designer Folder.
- In the Designer Folder, create a Flow. It will automatically open in the Flow Designer.
- After the Start step, add and connect a Setup Process Folder step by either searching for or by expanding the Process section of the Toolbox.
- Select the Setup Process Folder to view its Properties. Under the Parent Folder section, click PICK and choose the previous made Folder: 'ExampleFEEData'. Select PICK to confirm selection.
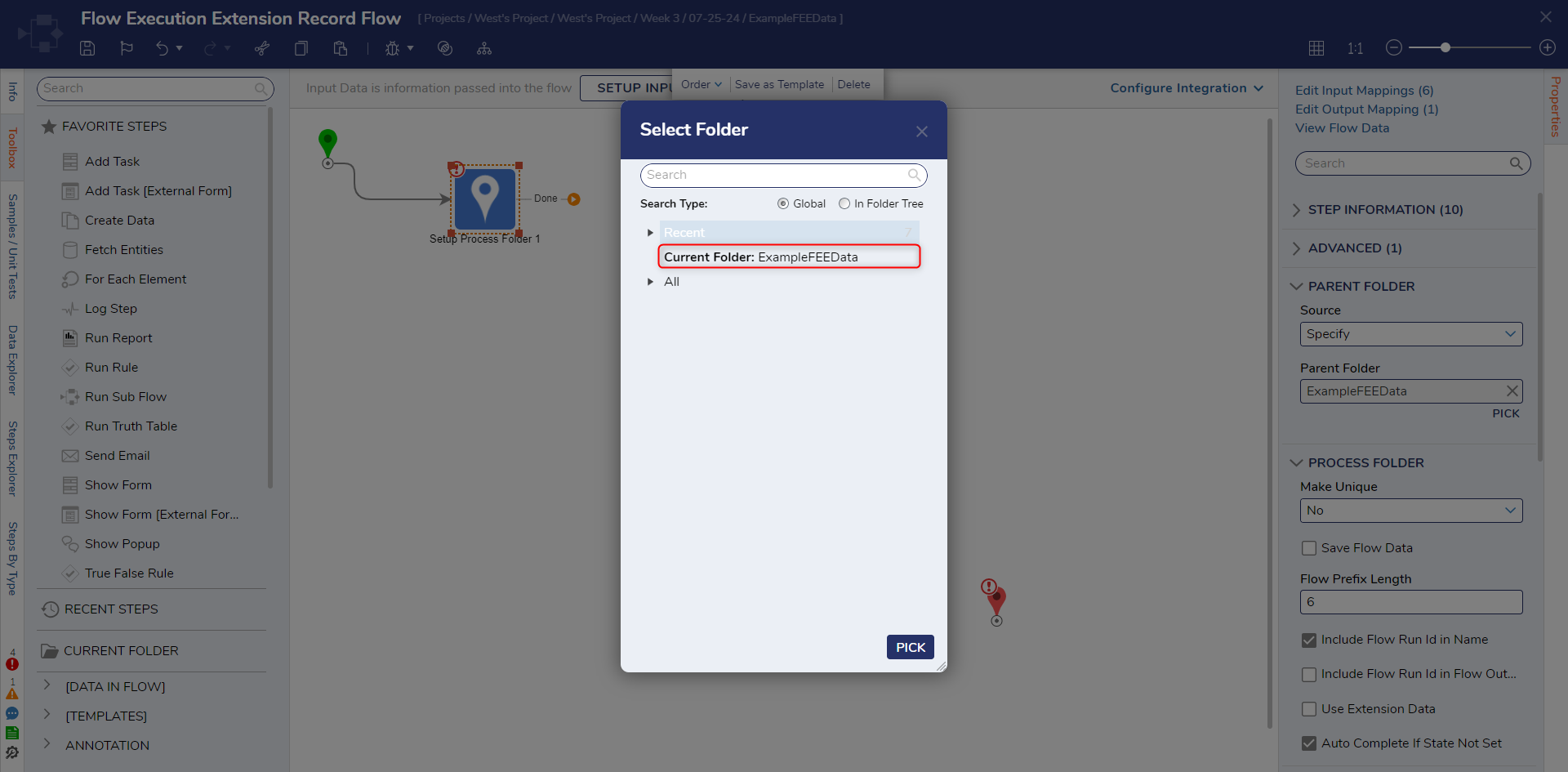
- Under the Process Folder section, change the Make Unique dropdown to Number so each record is uniquely numbered. Check the Save Flow Data setting to capture Flow Data alongside the data fields for each entry.
- Enable the Use Extension Data setting then, in the new Extension Data Type setting, search and select the created Flow Execution Extension: 'EmployeeApplication'.
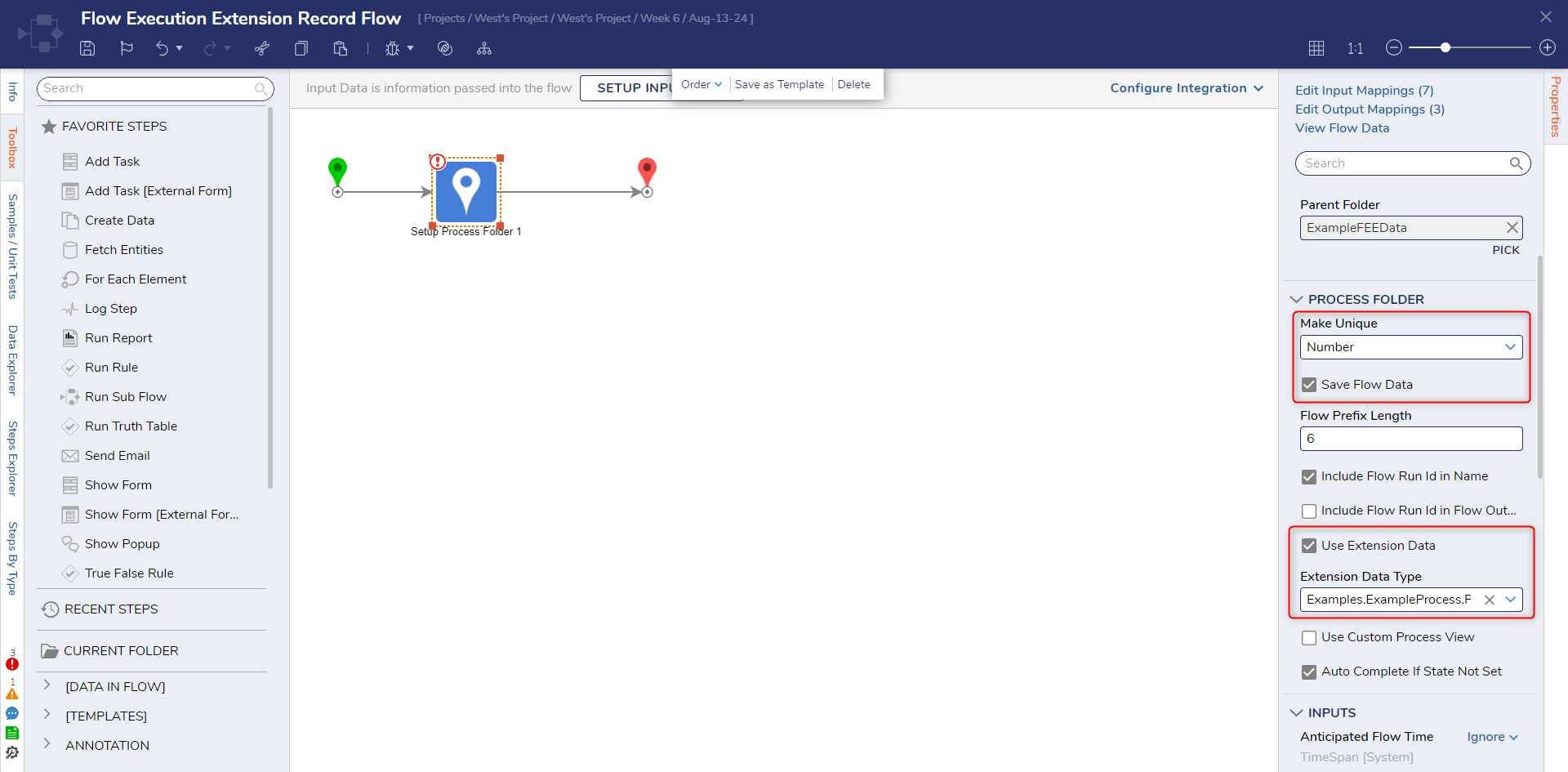
- Viewing the Inputs section, change the Extension Data input to Build Data. New child inputs appear including all data fields created for the Flow Execution Extension.
For each of the Flow Execution Extension's data field inputs and for the Folder Description and Folder Name inputs, provide example Constant data. Edit the Flow Prefix if the default is currently in use.Dynamically setting inputs to saveWhile this example uses Constant mapping to demonstrate the step logic, choosing the
Furthermore, it is a best practice to also dynamically set the Folder Description and Folder Name fields with the Merge Plain Text editor for more data-descriptive information. - Debug the Flow. Upon the Flow successfully running, right click on the Setup Process Folder step, expand the Execution 1 menu and select View Input/Output Data to view the data to be saved.
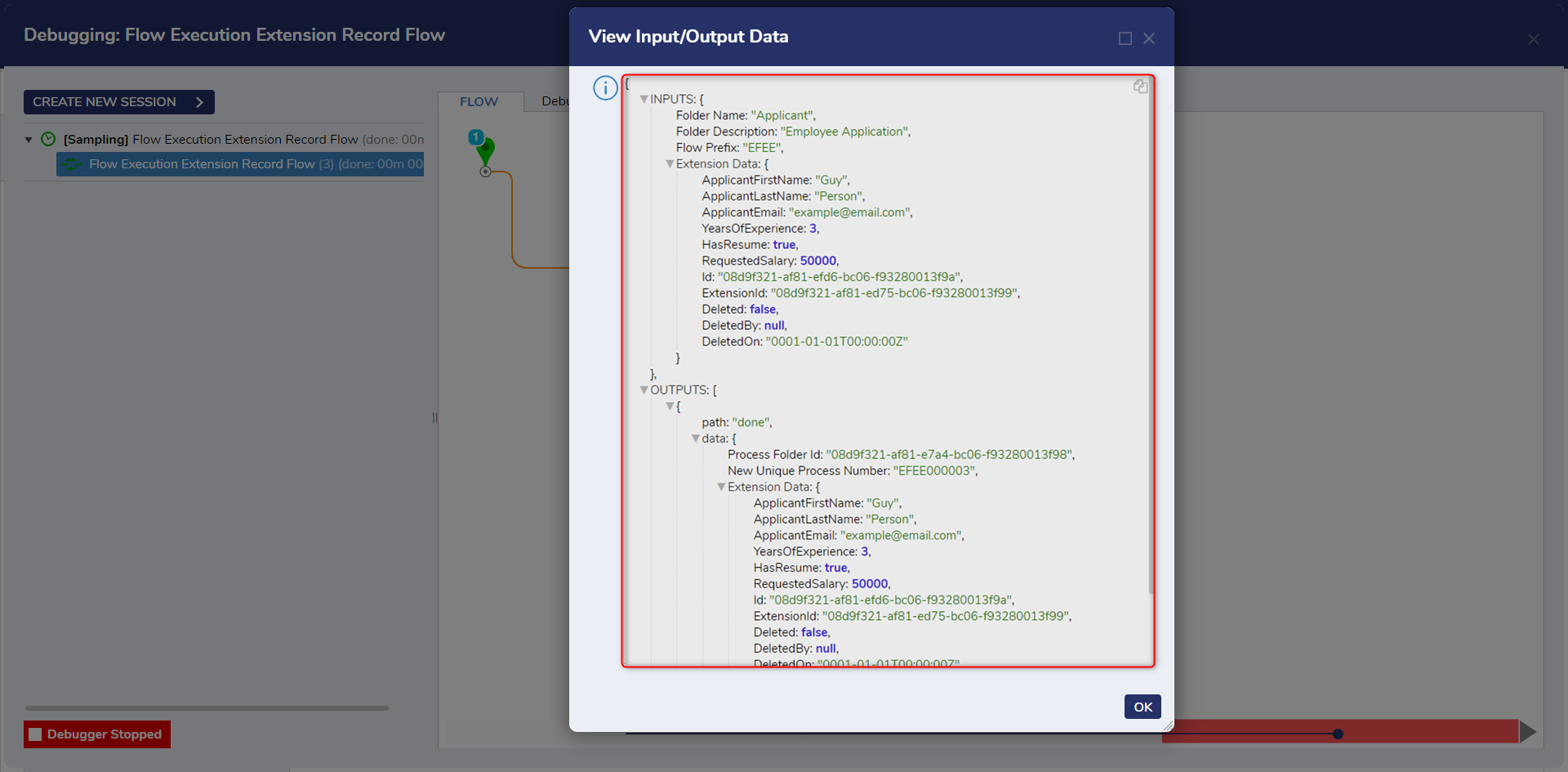
- Exit the Debugger. Save and close the Flow Designer to return the parent Designer Folder.
- Open the Folder selected to contain the process data: 'ExampleFEEData'. Notice it is now populated with an entry. Select the entry to open it in the Process View Page detailing an audit trail of its record, states, and any comments.
Customizing Process Viewing Options
Custom Process View Pages may be used to fit company branding and/or display other additional information relevant to the data stored.
- Select a Setup Process Folder step to open its Properties. Under the Process Folder section, set the Use Custom Process View setting to True.
- Two new settings are available: PICK OR CREATE CUSTOM VIEW PAGE and Custom View Page Name. Name this Page 'ExampleView' and then create a new Page. It will automatically open in the Page Designer.
- From the Favorites section of the Toolbox, add a Folder Activity Panel to the center workspace. Search and add a Horizontal Folder Timeline to the top portion for this example.
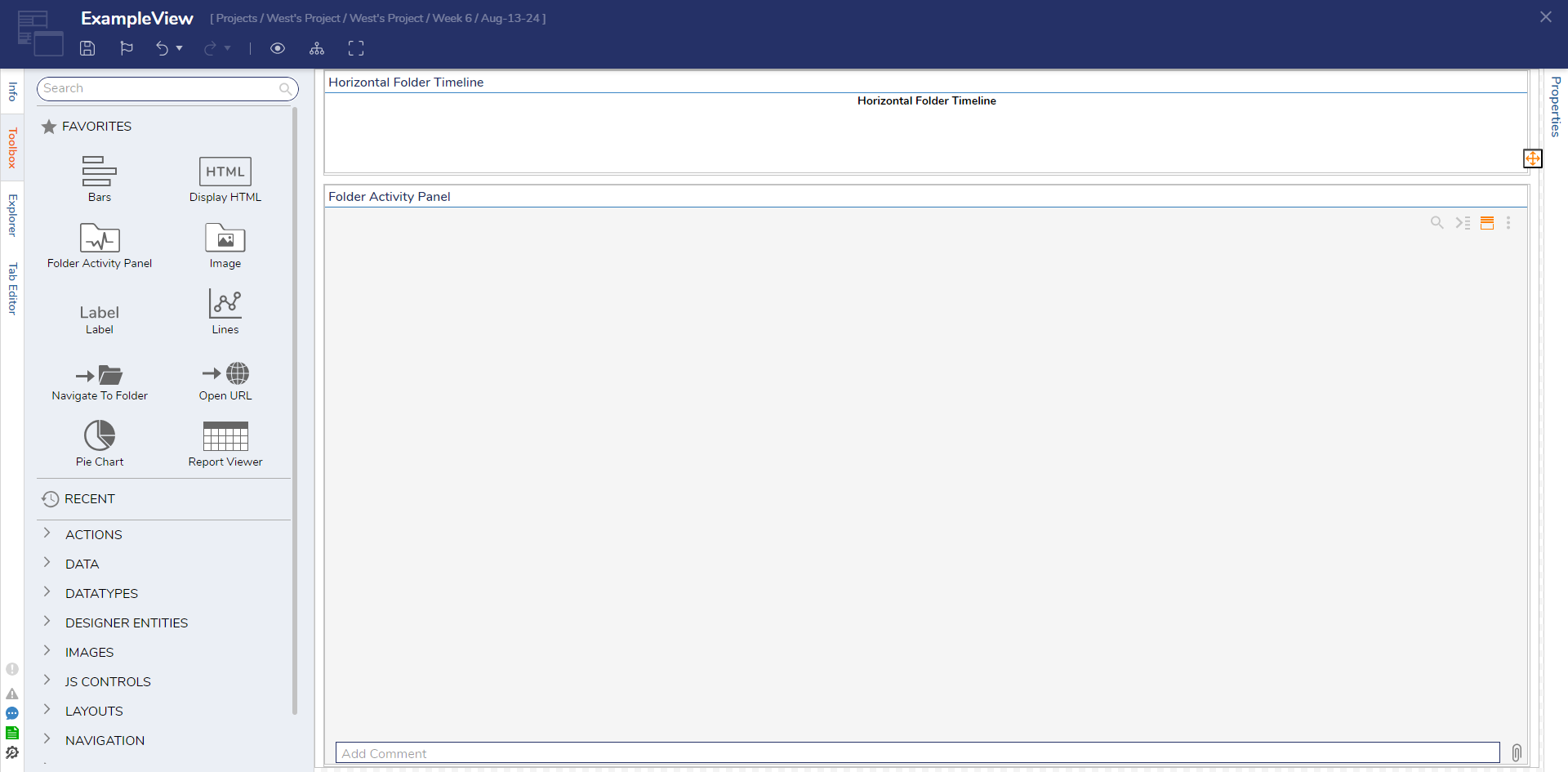
- Save and exit the Page Designer to return to the Flow Designer. Save and exit the Flow Designer to return to the Designer Folder.
- Right click on the Flow containing the Setup Process Folder step and select Run Flow.
- Open the Folder containing the Process Folder data. This example uses the prior example's folder: 'ExampleFEEData'. Notice the new entry.
- Click on the new entry to view the new custom Process View Page. Notice the old record still uses the default one since it was made before this change.
Feature Changes
| Description | Version | Release | Developer Task |
|---|---|---|---|
| Flow Execution Extensions have been deprecated. | 9.5 | November 2024 | [DT-041990] |