Overview
Before deciding which Data Structure(s) to introduce into a process or workflow, it is paramount to understand the supported functionalities for each option.
The first step towards this involves considering the nature of the process data as explained in its respective subsection.
From there, the Data Structure Selection Matrix infographic is a visual reference to what each Data Structure can or cannot perform.
Different kinds of Data Structures are suited to various applications and business needs. Users may construct their own custom Data Structures; however, not every use case will require one.
Nature of Process Data
One way to help narrow down which Data Structure to use is to determine whether the process data, not the Flow Data, is in motion or at rest.
| Data Movement | Description | Example |
|---|---|---|
| Data In Motion | This type of data exists only within the generating process. While not typical, it can be saved externally via saving the outcome. | A phone conversation or an approval process |
| Data at Rest | This type of data exists past the process. The saved data is contextual, and while it cannot change, its related variables might. In other words, it is inactive data. | A 'Person' is data at rest with variables such as 'Name,' 'Age,' and 'Clothing Size.' The 'Person' always remains a 'Person,' but the things related to the change. |
Data Structure Selection Matrix
The Data Structure Selection Matrix infographic provides a visual guide for each Data structure' capabilities and limitations.
Checkmarks denote support of a specific feature or factor, while Xs specify the opposite. For cases in between, clarifying text stands instead.
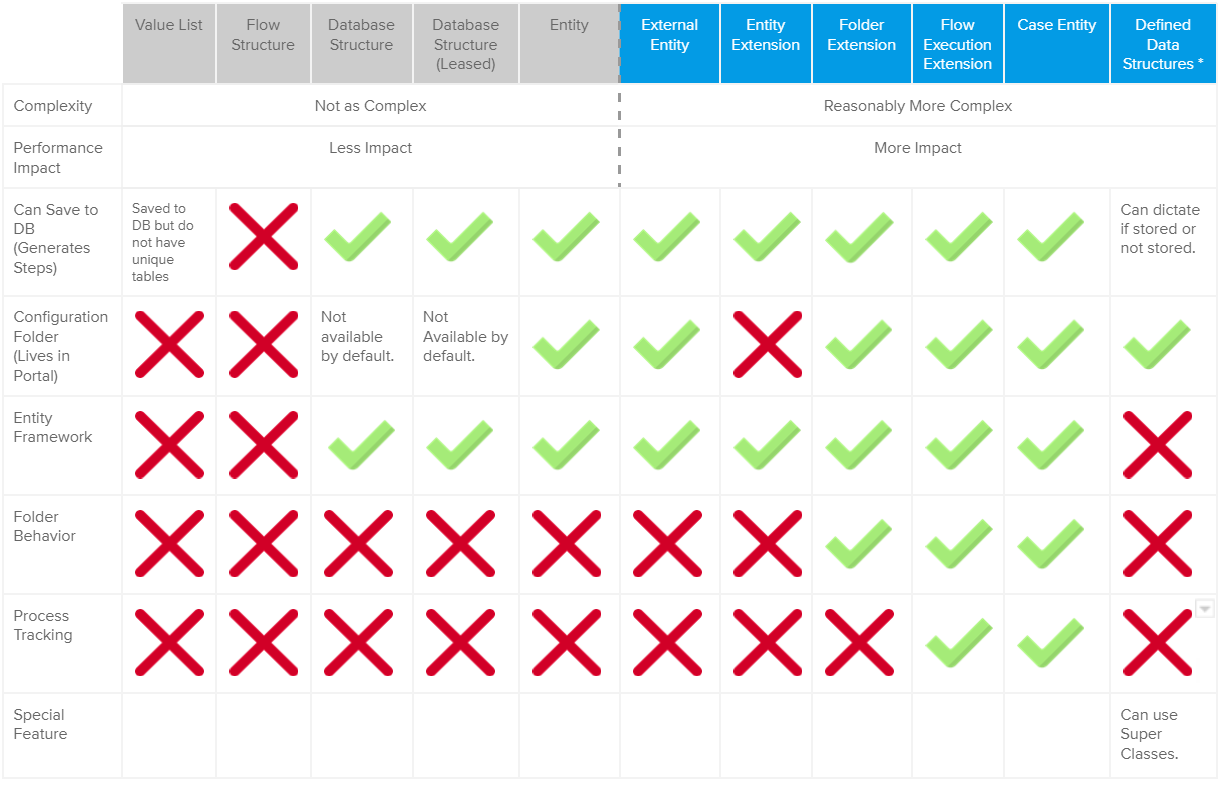
Understanding the Data Structure Selection Matrix
The above matrix displays several factors to consider when deciding which Data Structure to construct and how they may impact their process:
| Factor | Description |
|---|---|
| Performance Impact | The amount of strain that a structure introduces to the overall performance of the system. |
| Can Be Saved To A Database | Allows data storage in a Table in the database; creates custom-generated steps related to the Data Structure. |
| Configuration Folder | Automatically generates a Configuration Folder where CRUD, other User Actions, and Visibility Rules for the Data Structure reside. |
| Entity Framework | Adds an Entity Header Data Table, Folder View Report, and User Actions. Also uses Caching and is managed in Memory. |
| Folder Behavior | Adds a custom dashboard on a Folder, stores documents in Folders, and puts Assignments in Folders. |
| Process Tracking | Utilizes Process Folders to track the state of a process. |

Importing/Exporting Data Structures
In addition to using data and custom Data Types within a local environment, users may export data from Data Structures and import them to another Data Structure or a different Decisions environment. When deciding to migrate from one Data Structure to another, exporting then importing the data is a necessity.