Overview
Data Structures represent and organize business objects for internal logic processes with other Designer Elements such as Flows and Rules.
Data Structures consist of data fields detailing the data's properties, including their data type. An example Data Structure may be titled "Employee" with example data fields in quotations and Data types in parentheses: "Name"(String), "Age"(Int), and "Work Email" (Email).
Similar to other Decisions Elements, Data Structures along with their data may be imported/exported into other Decisions instances or external programs as a CSV file.
When to Use a Data Structure
During planning, consider the following questions when determining which Data Structure to use:
- Are processes object-oriented (a noun) or functional (a verb)? Which is considered first: the information to be processed or the transformation processes? If it's the former, it is recommended to use a Data Structure. If it's the latter, the focus should be on building flows and reports to generate the same results instead of using a custom Data Structure.
- What are the reporting needs, and do they involve more than process details? If user-defined data gathered and submitted in a Form should be included in a Report, then using Data Structure is recommended.
- How often does the data change, and does it need to track its history? If snapshots of data are required, for example, in a patient medical review process with a frequently changing condition status Form, it is recommended to save that Form's information to a database that maintains its history for reporting purposes.
- Lastly, how much information needs to be handled? It is recommended to build processes in functional blocks rather than in one large Flow, which may result in a cumbersome amount of mapping for each of these individual variables. It is more efficient to create one Data Structure that contains all those variables.
Think beyond the initial scope of the process when possible: first capture the initial request details and then add later process details. For example, if there is an approval step, it might be best to capture additional information such as an approval or rejection comment also be written into the Data Structure.
User Defined Data Structures
| Database Name | Short Description | Example |
|---|---|---|
| Case Entity | For unstructured data in a repeatable process with variable outcomes; progress via specified states | A 'PatientRecord' case tracking states such as inquiry, booking an appointment, assessing patient, etc., have varying outcomes. |
| Database Structure | Creates a database table dependent on other components to be manipulated (while there are no limits to the number of rows, more rows will increase query time) | A 'Customer' with data fields such as 'CustomerID', 'EmailAddress', etc. that are then formatted into a database table. |
| Defined Data Structure | Creates a database table dependent on other components to be manipulated; more memory efficient, so best for larger sets of data. | A large set of data 'Customer' with data fields such as 'CustomerID', 'EmailAddress', etc. that are then formatted into a table. |
| Entity | Creates a persistent Object and allows the ability to create actions specific to that object | An entity 'Person' with data fields like 'Age', 'Clothing Size', etc. These values can change, but the 'Person always remains a 'Person'. |
| Entity Extension | Creates a persistent Object that extends a preexisting type of Decisions | A 'Person' Entity with an 'Address' extension that can be attributed after the Entity's creation via an action. |
| External Entity | Works with Objects stored externally | Importing an XML/JSON file with a table of 'Products', 'ProductNumbers', etc. |
| Flow Execution Extension | Enables Flow data into process data to capture, display, and store data in motion; most commonly used. (This was deprecated in v9.5. Case Entity is recommended instead.) | An 'Employee Application' with data to save and refer to later, such as 'ApplicantName', 'ResumePDF', etc. |
| Flow Structure | Creates an Entity that lives solely within a Flow that cannot be stored; allows temporary organization of data only existing within the Flow. | A data repeater showing data from different tables of Data Structures. |
| Folder Extension | Creates a Folder that represents an Entity; can perform actions | An 'Insurance Policy' Folder Extension with actions like 'Renew Policy' or 'Cancel Policy' to perform on its Object. |
| Value List | Creates an enumerated list of string values that changes regularly | A drop-down list containing all fifty of the United States for a Form. |
Creating Custom Data Structures
In addition to Decisions' pre-built Data Structures, Designers may create custom Data Structures from the following schema types:
- CSV
- JSON
- JSON Schema
- XML
- XSD
Data Structure CRUD Actions
Designers and specified end users/groups interact with Data Structures through CRUD Actions: Create, Read, Update, and Delete, for easily updating data in Decisions. These actions are visible as steps for the specified Data Structure in the Flow Designer.
Data Structure Namespace
When creating a Data Structure, Type Name Space under the Advanced settings allows Designers to configure the namespace of the Data Structure. By default, this setting will populate with the folder path to the Data Structure, such as "MyApps.[ExampleFolderName]".
Data Structure names use the Project name - "MyApps.[ExampleProjectName]".
It is recommended to change this setting when working on large projects since this default folder path name will grow larger as the parent folder becomes further nested. Furthermore, multiple data structures with the same Name Space may exist. Changing the Name Space name may prevent future organization issues.
Projects or Folder names with diacritics will have those symbols removed upon upgrade.
Recompiling Data Structures
When Data Structures are giving errors, one thing a user can do is try using the Recompile Data Structures Action. This is found under Manage > Health > Data Structures.
- Right-click on the Data Structures folder, select Compile, and then select Recompile Data Structures. Or use the Recompile Data Structures action.
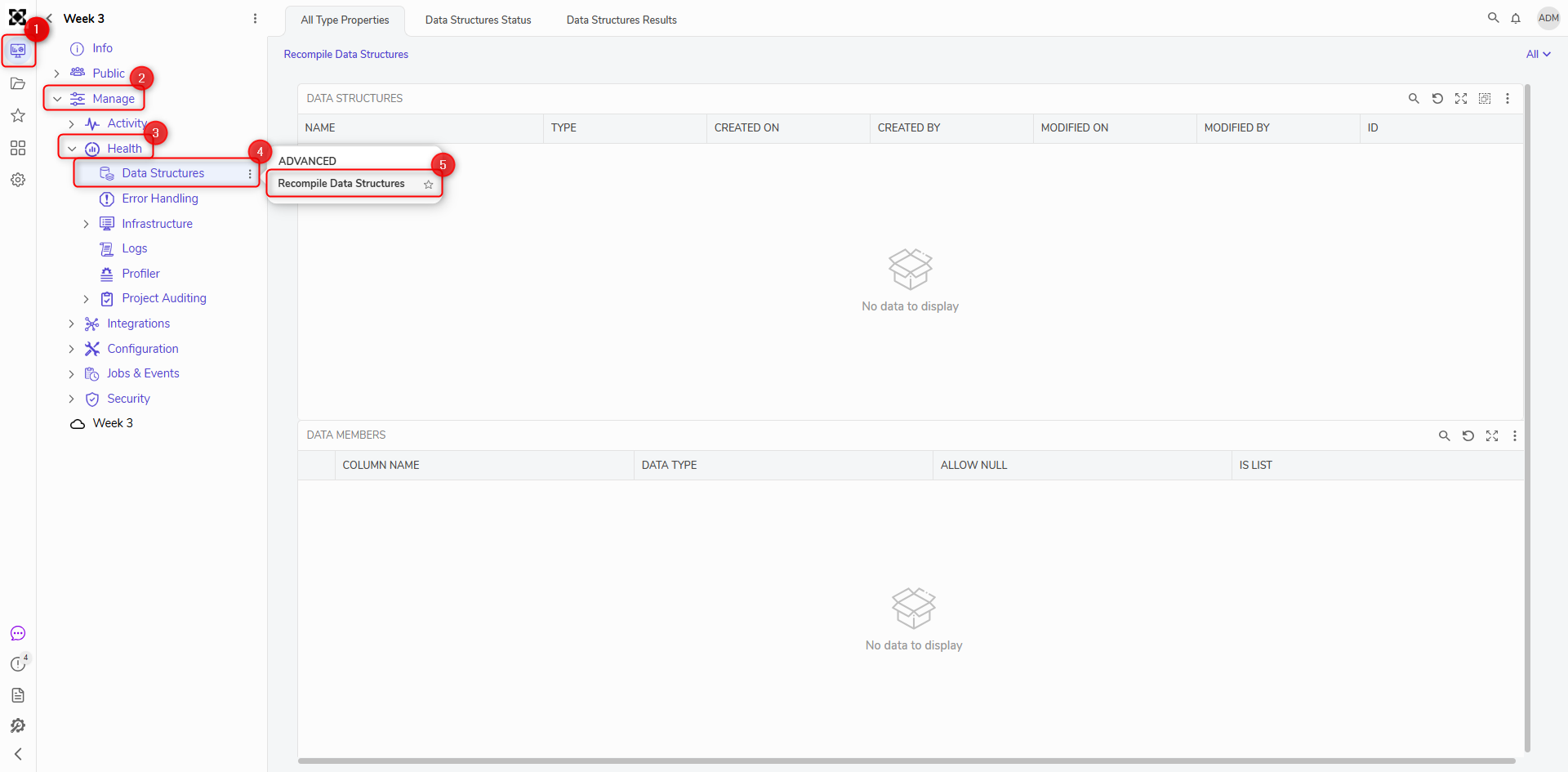
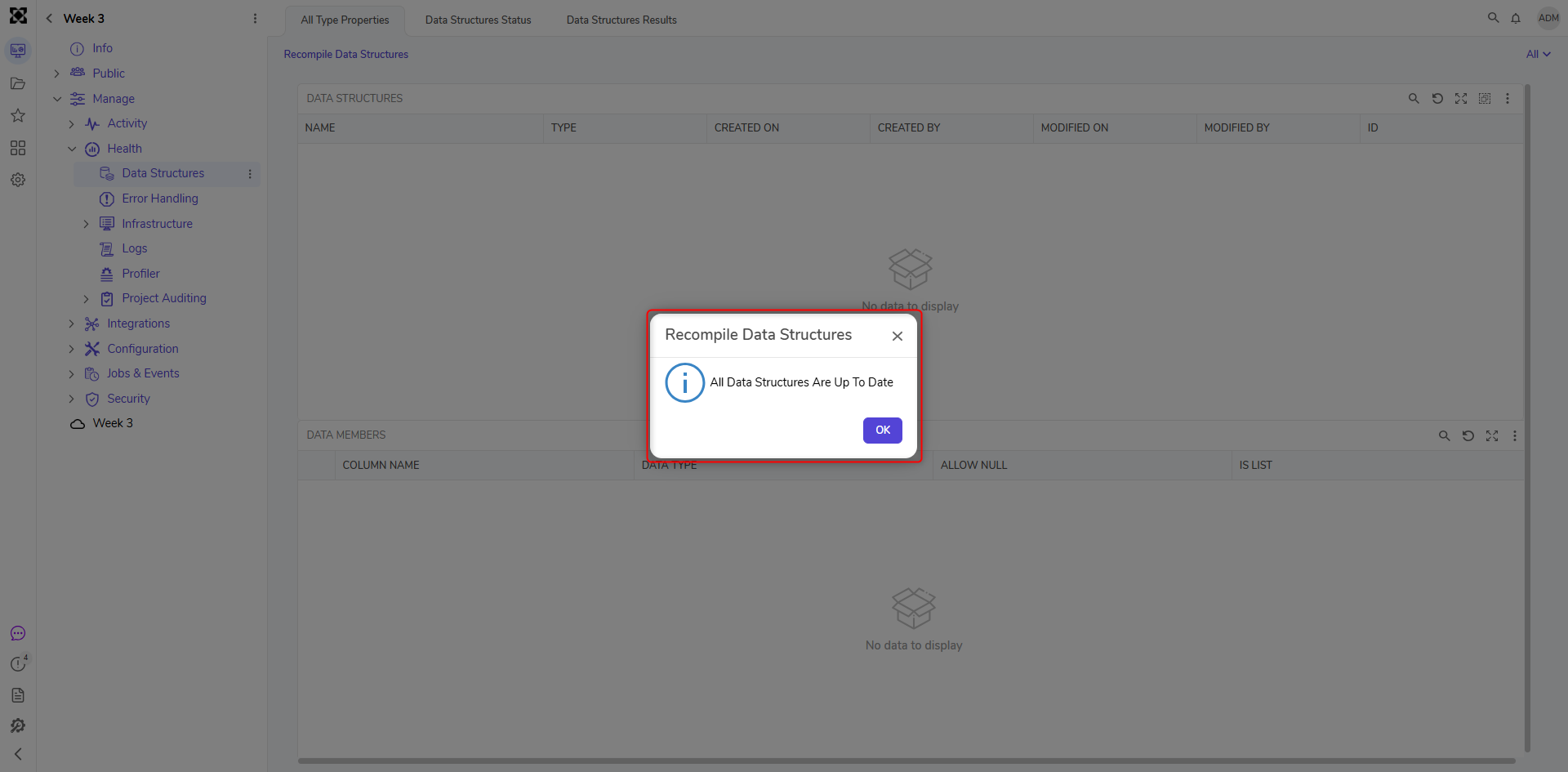
- A list of Data Structures that need to be recompiled or a popup window stating that All Data Structures are up to date will display. If a list appears, select the Data Structures that need to be recompiled and then click OK.
Feature Changes
| Description | Version | Release Date | Developer Task |
|---|---|---|---|
| Restrictions to using diacritics have been added. | 9.9 | April 2025 | [DT-043977] |
| The namespace will now be the Project name instead of the full file path. | 9.14 | August 2025 | [DT-038580] |