Overview
Data Caching is when a copy of data is temporarily stored in a designated location known as a Data Cache. This information is stored within a cache instead of a system file storage for ease of access and frequent use. Performance is greatly enhanced by caching. Users are able to interact with this information using a Flow or within the Designer Studio.
Caching Planning
Caching is an important part of project architecture and should be planned for. Below are some important notes about caching.
Data standards for Caching
Not all data is worth caching. Only data that is relatively stable is desirable. If cached data is of the sort that changes frequently it can cause issues where the user finds themselves processing data that is stale. A good example of relatively stable, infrequent updates would be a set of data that only updates at midnight each day. There is a set time for the update, so a caching system can be created with that in mind.
Even if a particular data record is a good candidate to be cached, not every field associated with that record needs to be cached. For instance in a ticketing system the ticket id number may never change and that field could be cached, but comments on the ticket or escalation status that could change often should not be cached.
Caching also has practical size limits. Millions of data points should not be cached.
Cached data should be specific, targeted to a goal, and stable.
| Data Example | Cache? |
| Data changes every few minutes | No |
| Data does not change | Yes |
| Data is limited | Yes |
| Data is stable and used in many look-ups | Yes |
| Data involves 17 million records | No |
Decisions Caching Systems
The Decisions cache is delinked from the outside database. Changes to the database will not reflect in cache until the cache has expired and is refreshed whether from a timer or a Flow. For diagrams see Caching Systems.
Cache Keys
Keys can be any unique thing. However, it is important to keep in mind that cache keys must be unique. Any data with duplicate cache keys will be overwritten by the most recent data.
Enable Caching is Default
Caching is enabled by default wherever the option is available. For instance:
.png)
Types of Caching
Bespoke Caching
Bespoke Caching is a type of data caching that is designed to cater more specifically to the user's needs. Bespoke Data Caches are managed with the intent to use steps and methodologies to add data items to a cache when the user needs to. This is achieved through a data save and retrieval pattern that intentionally utilizes the cache.
In order to save information to the cache and ensure that the right information is retrieved, data is stored and fetched using a Key via an input on the Put In Cache and Get From Cache Flow steps. Additional steps are available that allow users to clear or manage their data cache from the Flow Designer.
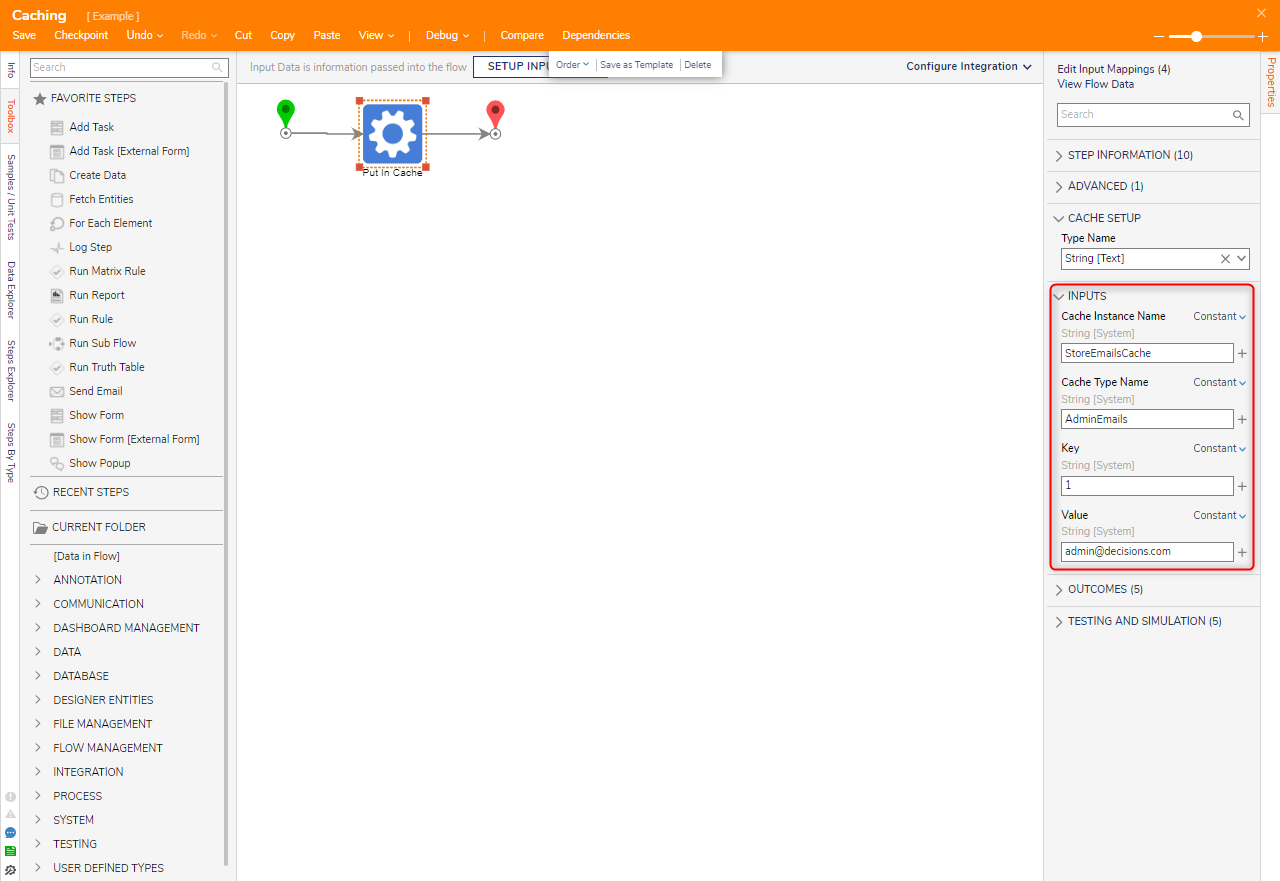
Outcome Caching
Outcome Caching is a type of caching that is established on the outcome paths of a step or multiple steps. Outcome Caching does not require specific caching steps. Upon saving data to the Cache, the information is stored for a set period of time via the Cache Timespan property that appears when a Cache Outcome is established on a step. This type of Caching is beneficial to instances that require a quick fetch or for users that want a copy of a Flow's outcome that can be quickly accessed.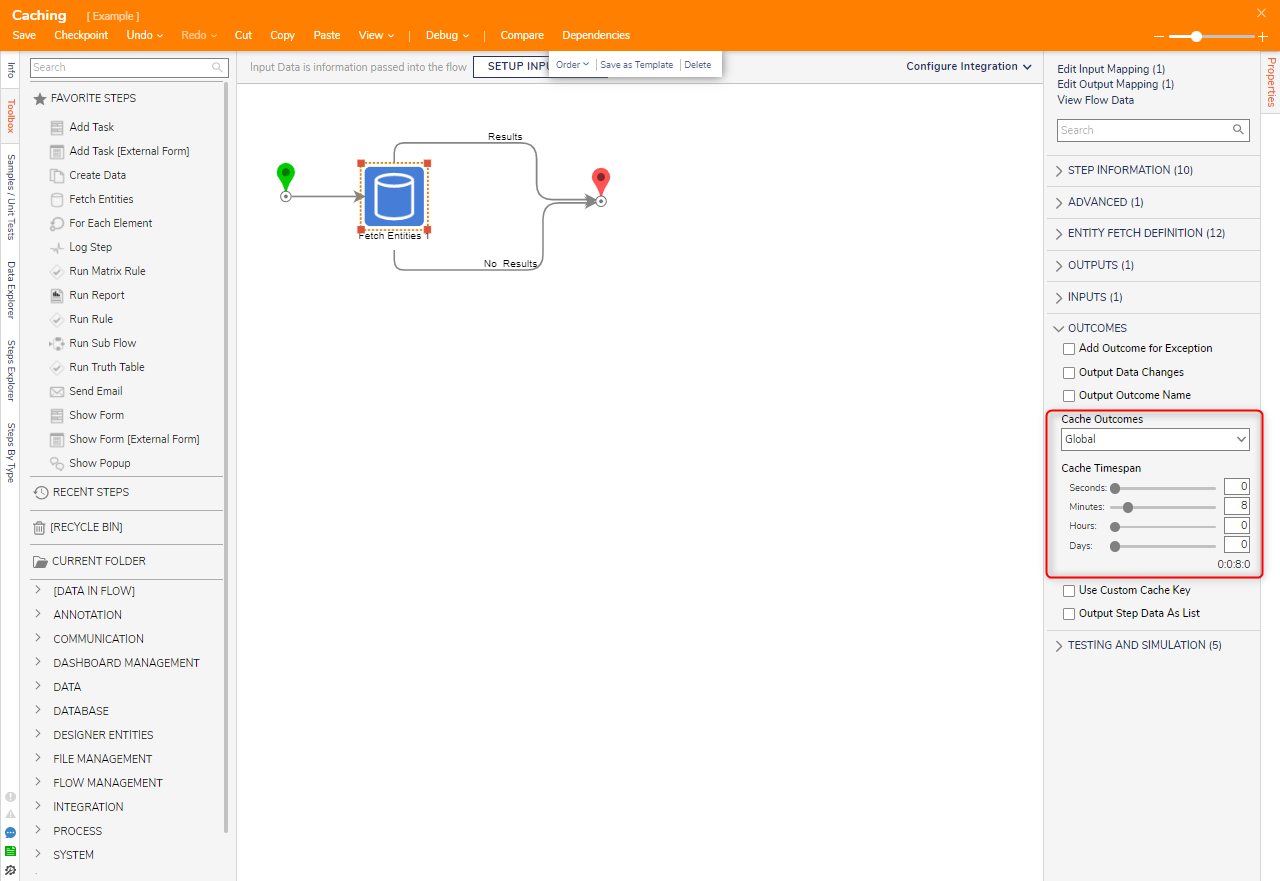
Bespoke vs. Outcome
| Style | Pro | Con |
| Bespoke | More control | Requires more set up |
| Outcome | Easy to set up and configure | Less control and flexibility, caching only happens based on timers |
Cache Definitions
In order to help users better customize the storage behaviors of their data caches, users may utilize the System Admin Cache Settings to establish a Cache Definition. Cache Definitions allow users to control the amount of time that items remain in a specific Cache, the size of the data stored within the Cache, the location of a Cache itself, etc. Additionally, Cache Definitions allow users to control different aspects of certain Cache Types, such as databases, files, or FileDirectory Caches. System Caches can be found by navigating to System > Administration > Cache and clicking ADD.
Caching Patterns
There are two patterns for caching. Below are descriptions of each, how to set them up, and best practice recommendations.
Just In Time
This pattern is best in clustered server environments because it allows the cache to be filled node by node.
The below mock-up is an example of a Just In Time and Bespoke Cache Flow. This Flow uses two Get From Cache steps, one Put in Cache step and one Is Empty rule.
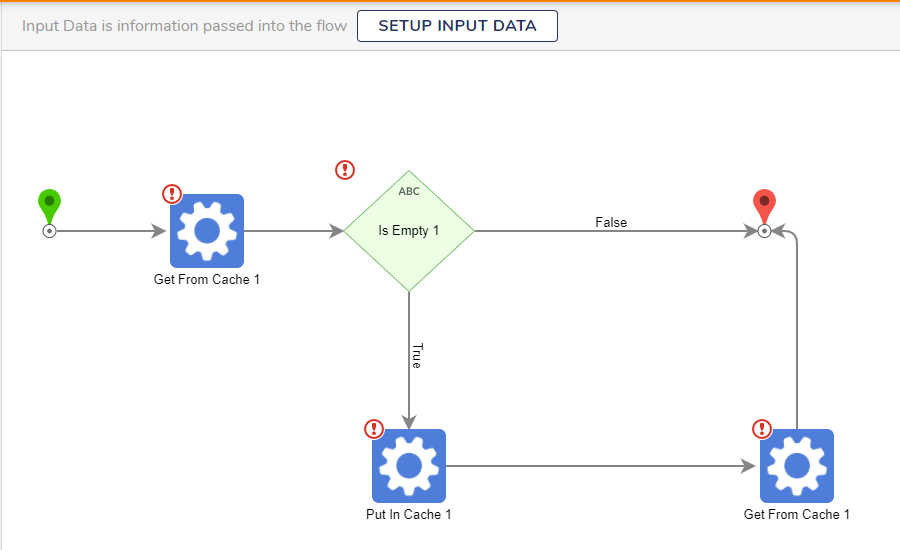
The Flow will check data in the cache, then run it through the Is Empty rule. Data that is not in the cache will be added with the Put in Cache step.
Prime The Pump
In this method data from the cache is loaded as soon as a server comes online to prefill desired forms, data structures, etc.
The issue with Prime The Pump is that it can burden the origin database when the Flow runs and all that data needs to be transferred into cache.
Additionally for versions 8.3 and below, in clustered server environments a system will need to be implemented to allow the cache to work across clusters.
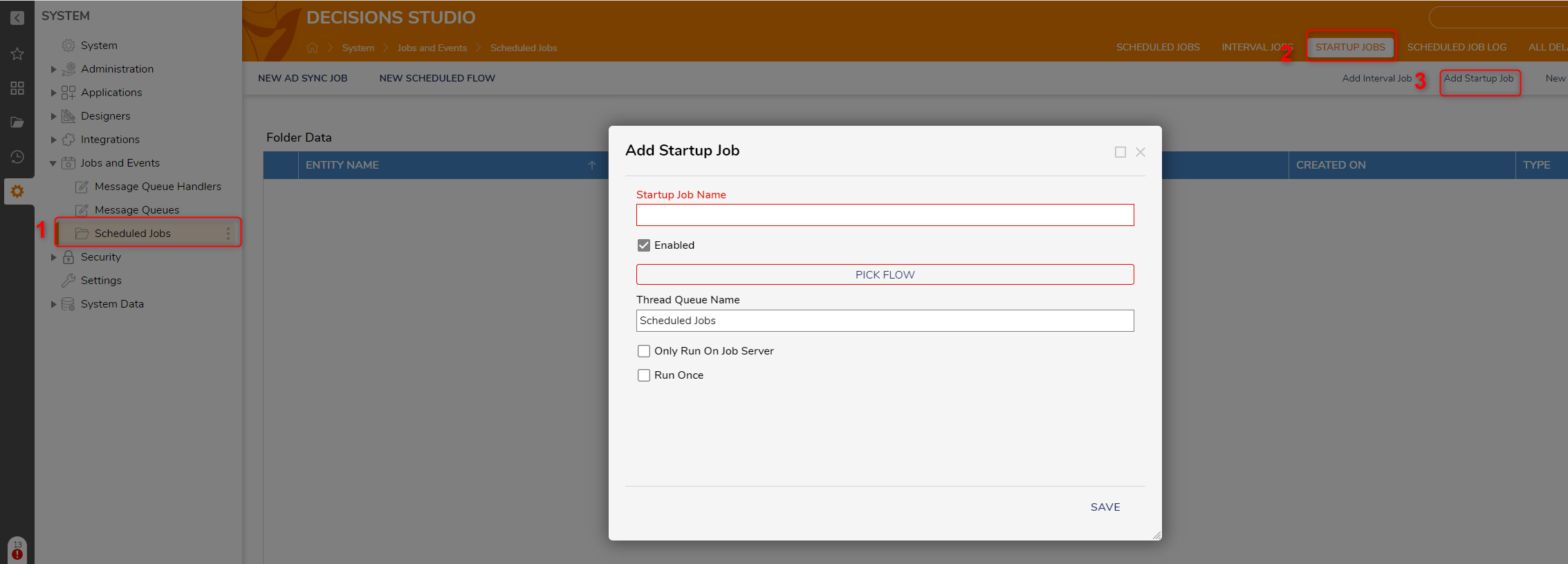
The best recommendation is to build a Scheduled Job that is set to run at startup or a Startup Job when the service comes online. This will keep cache loading service hit from happening at runtime.