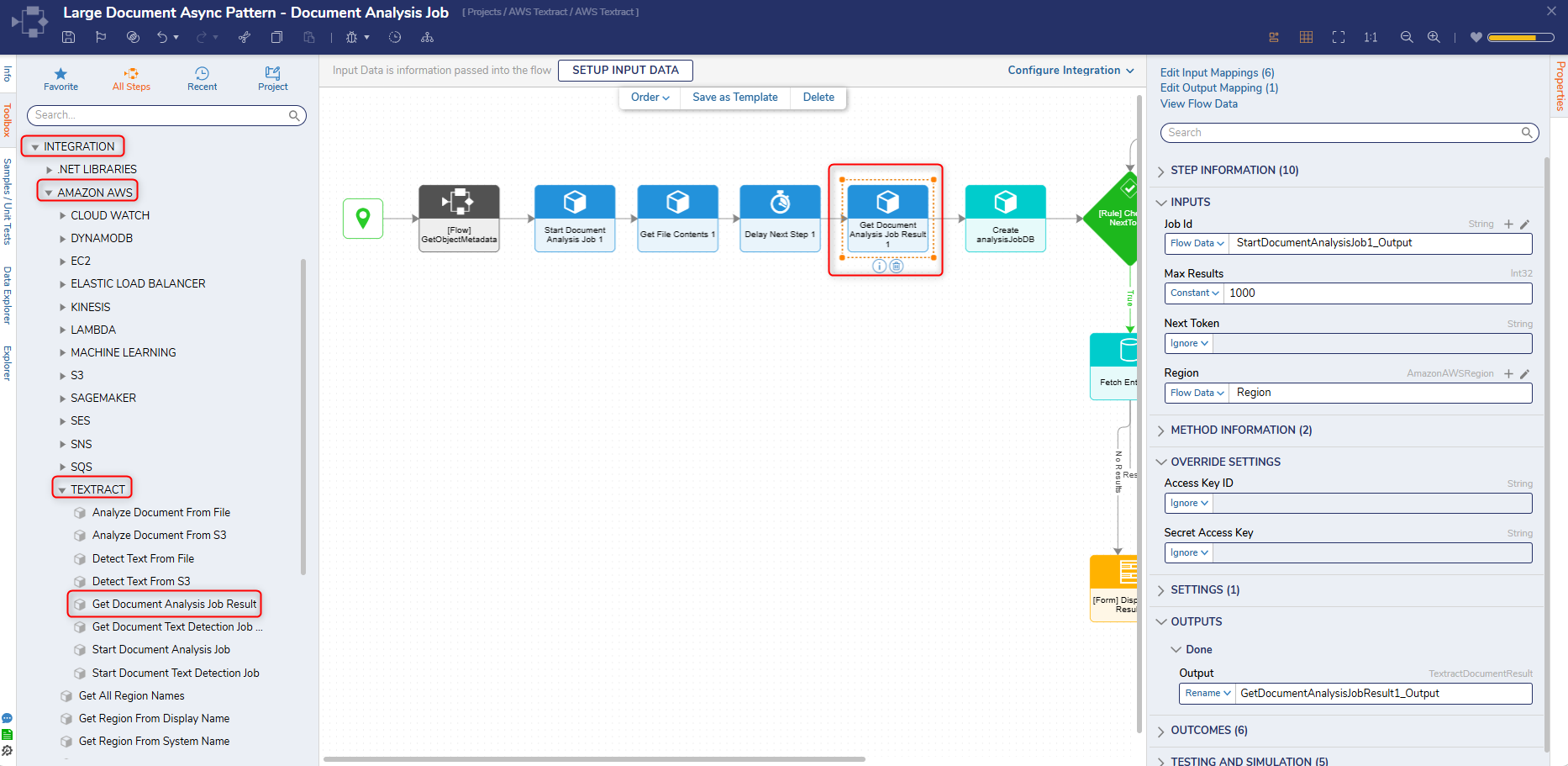
The Document Analysis Job Result step retrieves result pages for an async analysis job. Amazon Textract is an AWS service that automatically reads and extracts text, data, and tables from documents and images.
A dependency must be created after installing the module for the Step to be used properly.
Considerations
Asynchronous steps (Start Document Analysis Job, Get Document Analysis Job Result, Start Document Text Detection Job, Get Document Text Detection Job Result) can be used for larger multipage documents in the PDF or TIFF format.
Users may need to add a Textract Policy to their AWS user account to authorize access to the API.
Properties
Inputs
Property
Description
Data Type
Job Id
Takes in the Job ID from a Document Analysis Job.
String
Max Results
Allows Users to specify a maximum number of results. (default is 1000)
Int32
Next Token
Allows Users to specify an optional next token.
String
Region
Allows Users to specify a region.
AmazonAWSRegion
Override Settings
Authentication
If an Access Key ID and Secret Access Key are provided, those credentials are used.
If overrides are not provided, system/IAM credentials from existing AWS settings will be utilized.
If overrides are used, both override fields must be provided.
Users must ensure Textract permissions are present in the IAM policy for the selected credentials.
Property
Description
Data Type
Access Key ID
Allows Users to specify an Access Key ID for an AWS account.
String
Secret Access Key
Allows Users to specify a Secret Access Key for an AWS account.
String
Outputs
Property
Description
Data Type
GetDocumentAnalysisJobResult1_Ouput
Retrieves the Textract Document result.
TextractDocumentResult
Step Changes
Description
Version
Date
Developer Task
The AWS module has been updated with 9 additional steps that allow Users to access the Textract API.