| Step Details |
| Introduced in Version | 9.24 |
| Last Modified in Version | -- |
| Location | Integrations > Amazon AWS > Textract |
The Detect Text From S3 step performs text line detection on an S3 object. Amazon Textract is an AWS service that automatically reads and extracts text, data, and tables from documents and images.
Prerequisites
Considerations
- Synchronous steps (Analyze Document From File, Analyze Document From S3, Detect Document From File, and Detect Text From S3 are only intended for single-page documents. They can be used with the following file types: JPEG, PNG, PDF, TIFF.
- Users may need to add a Textract Policy to their AWS user account to authorize access to the API.
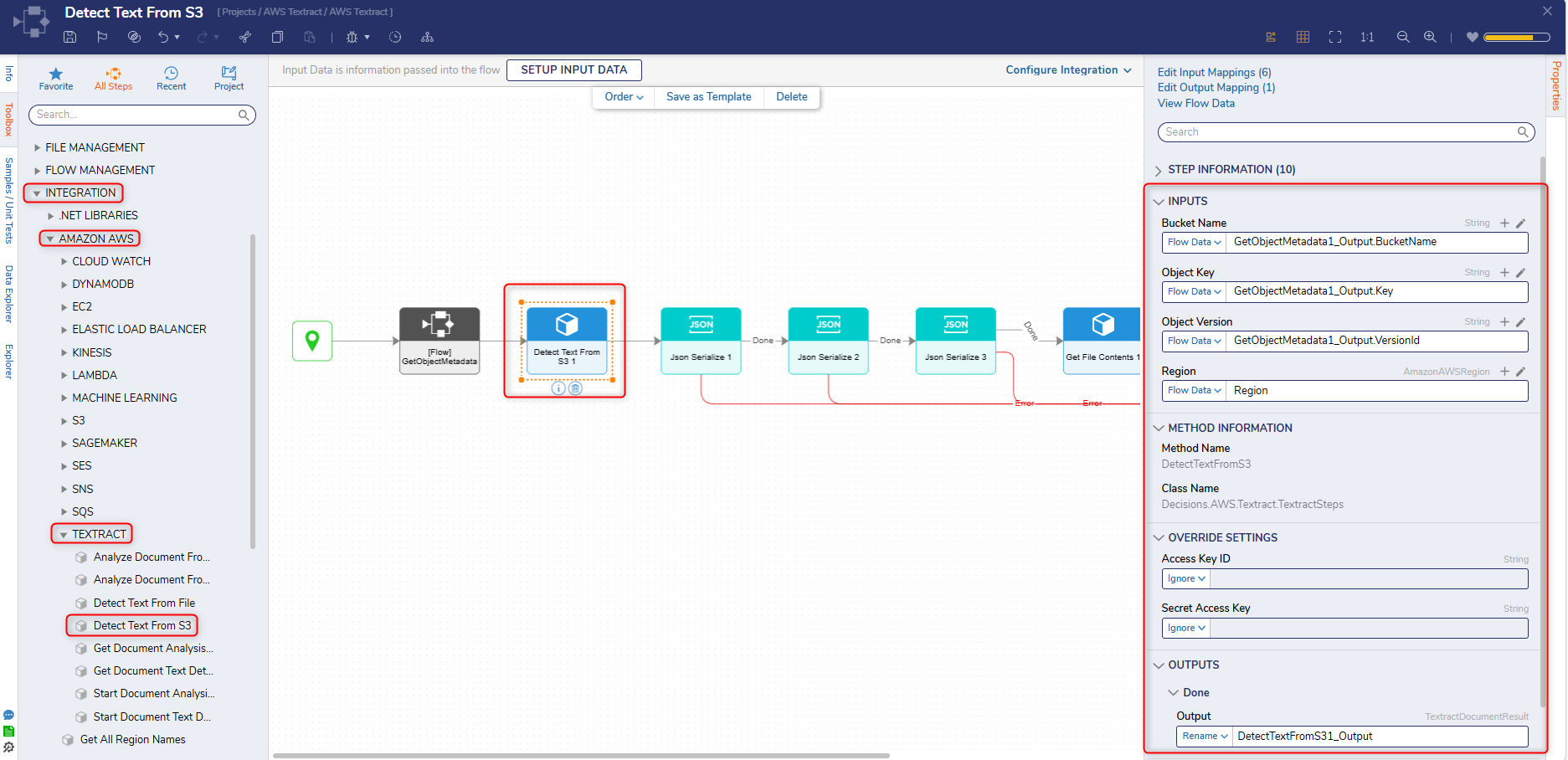
Properties
Inputs
| Property | Description | Data Type |
|---|
| Bucket Name | Allows Users to specify a Bucket Name for an S3 Object. | String |
| Object Key | Allows Users to specify an S3 Object. | String |
| Object Version | Allows Users to specify an S3 Object Version. | String |
| Region | Allows Users to specify a region. | AmazonAWSRegion |
Override Settings
| Property | Description | Data Type |
|---|
| Access Key ID | Allows Users to specify an Access Key ID for an AWS account. | String |
| Secret Access Key | Allows Users to specify a Secret Access Key for an AWS account. | String |
Outputs
| Property | Description | Data Type |
|---|
| DetectTextFromS31_Ouput | Retrieves the Textract Document result. | TextractDocumentResult |
Step Changes
| Description | Version | Date | Developer Task |
|---|
| The AWS module has been updated with 9 additional steps that allow Users to access the Textract API. | 9.24 | April 2026 | [DT-047247] |