Overview
Predictive modeling in Process Mining enables users to analyze historical data and build models that can forecast future outcomes or classify data points. This powerful technique helps organizations make data-driven decisions, optimize processes, and identify potential issues before they occur.
Currently, the System supports two primary types of predictive modeling:
- Classification: Predicts categorical outcomes, such as whether an event will occur or which category a data point belongs to.
- Regression: Predicts continuous numerical values, such as estimating process durations or resource consumption.
Users can select log or CSV files containing data to train models, apply these models to new data and monitor their performance. The predictive models can be deployed for ongoing use, enabling proactive decision-making and process optimization.
Using Predictions
The Predictions menu is located at the end of the Action menu. Users can choose from three options: Train Prediction, Predict, and Prediction Center.
Train Prediction
Training Prediction takes available data and then creates a model from it. To train a Prediction, first select a log or .CSV. The Garage Car Repair data is an easy way to test this feature.
After selecting data and pressing Train Prediction, the following menu appears:
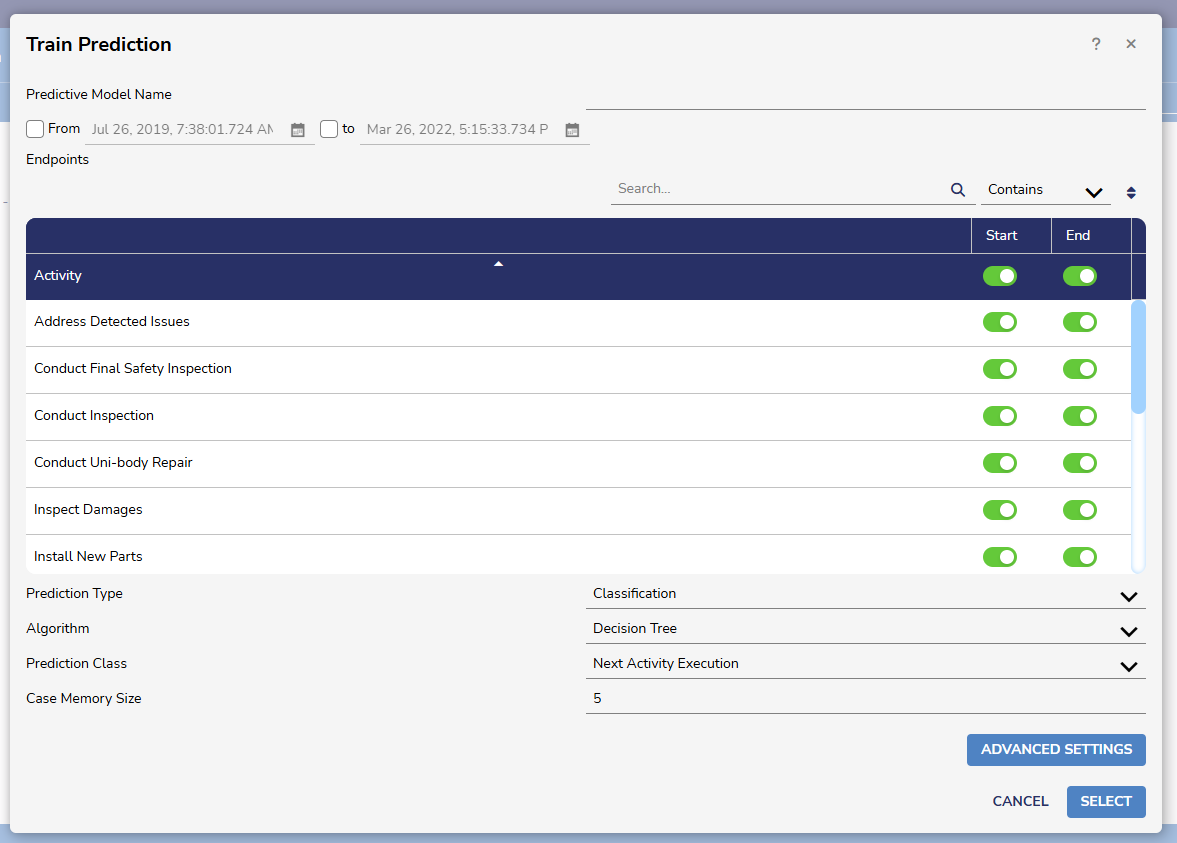
The Activity section contains all the attributes from the log or .CSV file.
Prediction Types
| Type | Description |
|---|---|
| Classification | Predicts categories (Can be binary (1/0 or yes/no or Multiclass classification) Example: Binary Classification: Spam email detection – the Machine Learning model learns from previously labelled emails (spam/not spam) to identify new spam. Multiclass Classification: Predict drug class – the Machine Learning model learns from previously labelled patient data and drug prescribed to that patient (drugA, drugB, drugC) to identify which drug can be prescribed for the new patient data. |
| Regression | Predicts continuous numerical values. This determines relationships between the Prediction Class and one or more variables, in this case the attributes of the data. Example: House price prediction based on features like size, location, etc. |
Algorithm
| Type | Description |
|---|---|
| Decision Tree | A decision tree is similar to a flowchart that makes decisions based on features. It can be used for both classification (DecisionTreeClassifier) and regression (DecisionTreeRegressor) tasks. Example: Predict if a customer will buy a product based on age and income. |
| Random Forest | Random Forest combines multiple decision trees to make more accurate predictions. Example: Predicting house prices based on size, location, and number of rooms. |
| XGBoosted Trees | XGBoost is an advanced version of decision trees that build trees sequentially, each correcting errors of the previous ones. Example: Predicting customer churn for a telecom company based on usage patterns and demographics. |
| Factorization Machines | Factorization Machines are a general-purpose supervised learning algorithm that can be used for both classification and regression tasks. This algorithm is good at capturing interactions between features. This is especially useful for recommendation systems. Example: Recommending movies to users based on their past ratings and movie features. |
| Kernel SVM | SVMs are supervised learning methods used for classification, regression and outliers' detection. SVM uses different types of kernels which are mathematical functions like Linear, Polynomial, Radial Basis Function and Sigmoid. Example: Classifying images of cats and dogs based on pixel values. |
| Linear Stochastic Gradient Descent | This is an optimization algorithm used in machine learning, particularly for linear models like linear regression and logistic regression. Compared to other optimization algorithms, LinearSGD can be faster for training linear models, especially when dealing with large datasets. This is because it avoids complex calculations needed for non-linear models. Linear Stochastic Gradient Descent is primarily suitable for linear models. It might not perform well with complex, non-linear models that require more sophisticated optimization techniques. |
| LibLinear | LibLinear is a library for large-scale linear classification, useful for text categorization or sentiment analysis. Example: Classifying news articles into categories like sports, politics, or technology. |
| LibSVM | This is a simple library for solving large-scale regularized linear classification and regression. It implements the sequential minimal optimization (SMO) algorithm for kernelized support vector machines (SVMs), supporting classification and regression. |
| Multinomial Naive Bayes | This algorithm is particularly useful for text classification tasks, assuming features are independent. Example: Classifying customer reviews as positive, negative, or neutral based on the words used. |
Predict
The Predict action allows the user to apply a predictive model against an imported log or .CSV file. As long as the file has the same characteristics as the model, it will provide a Probability column indicating how the data would perform.

Prediction Center
After creating a predictive model, it can be found within the Prediction Center.

- The model's name is set when it is created. It can be renamed at any time by right-clicking on the name.
- The ID field is used to distinguish models from each other at the System level. When calling a model within Decisions, this ID number is critical.
- The algorithm is determined at the time of creation. See the section above for more information on the different types.
- The prediction class is the target variable the modeling process estimates during prediction.
- Predictive models can have one of six different statuses.
- Generating: This status will show up while the predictive model is still being trained.
Ready: This status will show up once the generation of the predictive model is completed.
Deployed: This status will show up for predictive models that are currently ready and deployed.
Ready (Unstable): This status will show up once the predictive model generation is completed, but the model is unstable. A model may be unstable when it is based on a classification algorithm and cannot predict all possible target labels. Quality measures for unstable models are not available.
Deployed (Unstable): This status will show up for unstable predictive models currently ready and deployed.
Failed: This status will show up when the generation of the predictive model fails.
- Actions
| Icon | Name | Description |
|---|---|---|
 | Predictive Model Properties | This opens the Confusion Matrix screen, giving Users insight into how the model will function. |
 | Ready | Changes the status of the model from Ready to Deployed. |
 | Download | Allows Users to download a DMN representation of the highlighted model. |
 | Create Rule Table | Allows Users to create a Rule Table from the highlighted model. |
 | Delete | Deletes the highlighted model. There is no confirmation screen, and this action is permanent. Be careful when using this action. |
Creating a Rule Table from a Prediction Model
Users can convert trained prediction models that use the Decision Tree algorithm into a Rule Table within the Decisions Platform.
- Navigate to the Prediction Center from the Process Mining home page.
- Highlight the desired Prediction Model and select Create Rule Table.

- Note: A warning will appear for Prediction Models that will take a long time to generate. Users can click "No" to cancel the process or click "Yes" to proceed.

- Note: A warning will appear for Prediction Models that will take a long time to generate. Users can click "No" to cancel the process or click "Yes" to proceed.
- A window will appear prompting Users to provide additional details. From here, click either Create New Project or Select Existing Project. Users will need to provide a name for new projects or select existing projects from the provided dropdown. Once all details have been completed, click Export to proceed.

- Users will receive a notification that the Rule Table is currently being processed. Click Ok to proceed.

- This action will create a new Project in the connected Decisions instance.

- Users can navigate to the Project to view the created Rule Table.

- Users can navigate to the Project to view the created Rule Table.
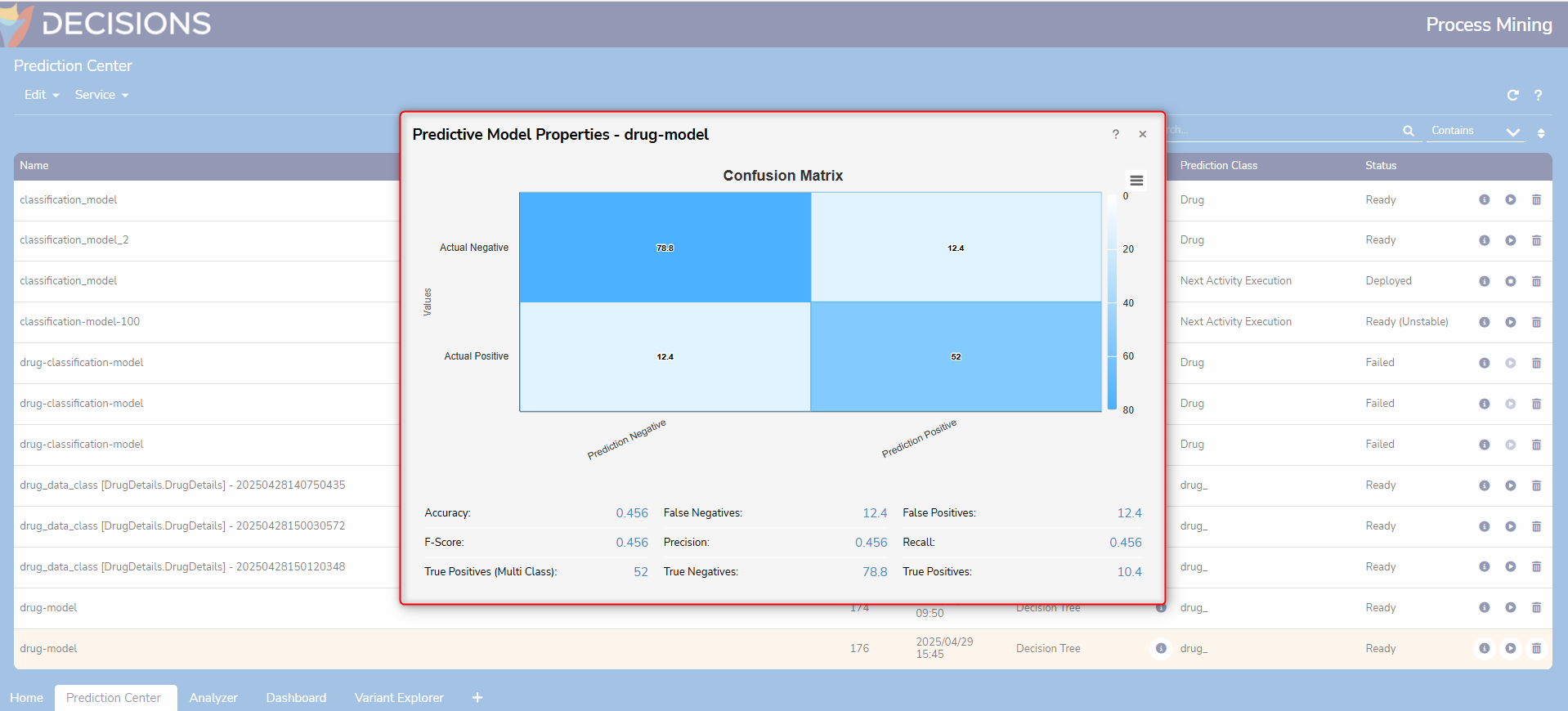
Confusion Matrix
A Confusion Matrix is a key evaluation tool in predictive modeling, especially for classification tasks. It provides a detailed breakdown of the model’s performance by comparing actual versus predicted outcomes. This matrix helps users understand not just overall accuracy, but also where the model is making errors.
During model training, the System splits the data into 70% for training and 30% for testing. The Confusion Matrix is calculated using this 30% testing dataset. The total number of instances in the matrix equals the sum of False Negatives (FN), False Positives (FP), True Negatives (TN), and True Positives (TP). Values may appear as decimals for multiclass classification, as they are averaged across all classes.
Confusion Matrix for Binary Classification
In binary classification, the Confusion Matrix is a 2x2 table showing how well the model distinguishes between two classes (e.g., "Yes" vs "No", "Positive" vs "Negative"). The matrix is structured as follows:
| Predicted | ||
|---|---|---|
| Actual | Positive | Negative |
| Positive | True Positive (TP) | False Negative (FN) |
| Negative | False Positive (FP) | True Negative (TN) |
- True Positive (TP): Model correctly predicts the positive class.
- True Negative (TN): Model correctly predicts the negative class.
- False Positive (FP): The model incorrectly predicts a positive when it is actually negative (Type I error).
- False Negative (FN): The model incorrectly predicts negative when it is actually positive (Type II error).
The sum of all four values equals the total number of test instances. These numbers help compute accuracy, precision, recall, and F1-score metrics.
Confusion Matrix for Multiclass Classification
For multiclass classification, where there are more than two possible outcomes, the Confusion Matrix expands into an n x n table (where n is the number of classes). Each row represents the actual class, and each column represents the predicted class.
In multiclass scenarios, the values in the matrix may be decimal numbers. This is because the system computes averages across all classes to provide a balanced evaluation, especially when class distributions are uneven.
| Predicted | |||
|---|---|---|---|
| Actual | Class A | Class B | Class C |
| Class A | TPA | FPBA | FPCA |
| Class B | FPAB | TPB | FPCB |
| Class C | FPAC | FPBC | TPC |
- The diagonal elements (e.g., TPA, TPB, TPC) show correct predictions for each class.
- Off-diagonal elements represent misclassifications between classes.
By analyzing the Confusion Matrix, users can see which classes are most often confused with each other and identify areas for model improvement. Using averaged (decimal) values ensures fair evaluation even in complex, multiclass situations.
How the Confusion Matrix is Displayed in Decisions - Process Mining
The Confusion Matrix is always presented as a 2x2 table, regardless of working with binary or multiclass classification problems. The matrix displays the actual counts of True Positives, True Negatives, False Positives, and False Negatives for binary classification.
Instead of showing a larger matrix for multiclass classification, it calculates and displays the average values for TP, TN, FP, and FN across all classes in the same 2x2 format. This means seeing decimal numbers in the matrix, which represent the mean performance of the model for each class, averaged over all possible classes. This approach provides a clear and consistent summary, making it easy to compare model performance even as the number of classes increases.
This averaged 2x2 confusion matrix helps users quickly understand overall model accuracy and error distribution, without needing to interpret a more complex, multi-dimensional matrix.
Sampling in Predictive Models
What is Sampling and why is it Important?
In the context of Predictive Models (Regression, Classification, etc.), Sampling refers to the process of selecting a subset of data points from a larger dataset to use for building, training, validating, or testing the model. Samples allow Users to train models and make predictions, since working with the entire population (all possible data points) is not always possible.
Utilizing Sampling to Support Unbalanced Datasets
Unbalanced data occurs when one category has a disproportionate number of examples compared to others in a sample. If one class dominates in the sample, the model may perform poorly on minority classes.
For example, a Predictive Model is created to detect fraudulent transactions; 99% are normal, and 1% are fraudulent. If the model always predicts "normal," it is 99% accurate, but not useful since it misses fraud causes.
Process Mining utilizes Oversampling and Undersampling to automatically address imbalanced data and handle it.
Oversampling and Undersampling
Oversampling and Undersampling are two techniques that are mainly used when unbalanced datasets occur.
- Oversampling Minority Class: More samples are added to the rare class.
- Undersampling Major Class: The number of normal cases is reduced to match rare cases.
Example
Users can train a Predictive Model with either oversampling or undersampling using the steps below.
- Select a Event Log or CSV file and click on the Predictions > Train Prediction menu on the Process Mining home page.

- From here, choose a name for the Predictive Model and select Oversampling or Undersampling for the Sampling Method. In this example, Oversampling is used.

- A window will appear notifying Users that the Predictive Model has been added to the Prediction Center.

- Navigate to the Prediction Center by clicking on the Predictions menu again, then selecting Prediction Center. The screen will display all Predictive Models currently available in Process Mining. Users can view the Predictive Model based on the statuses shared previously (Generating, Ready, etc.)

- Right-click on the Predictive Model and select Predict, then select a Log from the next window.

- This action will populate predictions based on the selected Predictive Model with Oversampling.

Feature Changes
| Description | Version | Release Date | Developer Task |
|---|---|---|---|
| Predictions will now offer Users the option to address imbalances through oversampling and undersampling automatically. | 3.7 | September 2025 | [DT-044243] |
| Prediction Models that utilize the Decisions Tree Algorithm can now be converted into a Rule Table in the Decisions Platform. | 3.7 | September 2025 | [DT-044292] |