Recommended Architecture
The architecture diagram illustrates a Decisions clustering setup that is commonly used in load-balanced cluster deployment to handle client requests efficiently. Let's break down the components and their interactions.
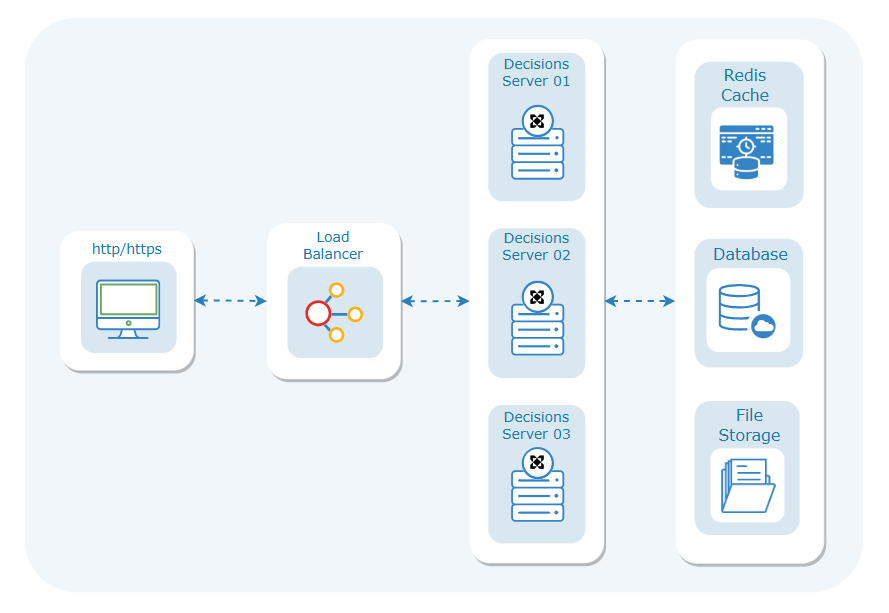
Client Requests (http/https):
These are http or https requests initiated by end-users or external systems to access the services. All the incoming requests are directed to the load balancer.
Load Balancer:
The load balancer evenly distributes incoming client requests across multiple servers. It ensures even distribution of requests among the servers, preventing overload on any single server and optimizing resource utilization. For more information, refer to About Load Balancing.
Decisions Servers:
These virtual machines in the cluster host individual application servers responsible for handling client requests, executing application logic, processing database queries, retrieving data from Redis Cache, and managing file storage. For more information, refer to the Hardware Specifications required for the servers.
Database:
A centralized database that stores and manages persistent data used by the application. Servers interact with the database to store and retrieve structured data. The database ensures data durability and consistency. For more information, refer to the Database Server and Configuration.
Shared File Storage:
A centralized file storage system accessible by multiple servers in the cluster for storing and retrieving files, such as images, documents, or multimedia. This allows for a centralized repository, making it easier to manage and scale file storage.
File Storage must be NTFS. In terms of deployment, organizations can host shared file storage on-premises or in the cloud.
Redis:
Redis is a high-speed in-memory data store used as a cache. The Decisions servers and the Redis server communicate via a series of API calls to store and retrieve Objects. The servers store information that helps to identify which node owns specific data. For example, If a user starts a Flow on Node A, Decisions will store the Flow tracking ID and it’s owner as Node A in Redis. For more information, refer to Setting Up Redis External Caching.
Data Management in Cluster
Data stored in clustering is managed in a way similar to data in a normal Decisions instance. The table below defines how data is handled in a clustered environment.
Saved to Database | Saved to File Storage | Saved to Redis |
|---|---|---|
Flows | Documents - PDFs, Docs, etc. | Ownership of the entity data |
Rules | File Reference Entities | |
Forms | Icon Library | |
Created Data | Custom SDK | |
Accounts | ||
.dbo Documents | ||
Data Structures | ||
CSS |
Types of Clustering Deployment
The previous section provided information about setting up a load-balanced cluster, which is highly recommended for deployment purposes. However, there are alternative deployment methods you can use to deploy decisions in a cluster.
User-Distributed Cluster Setup
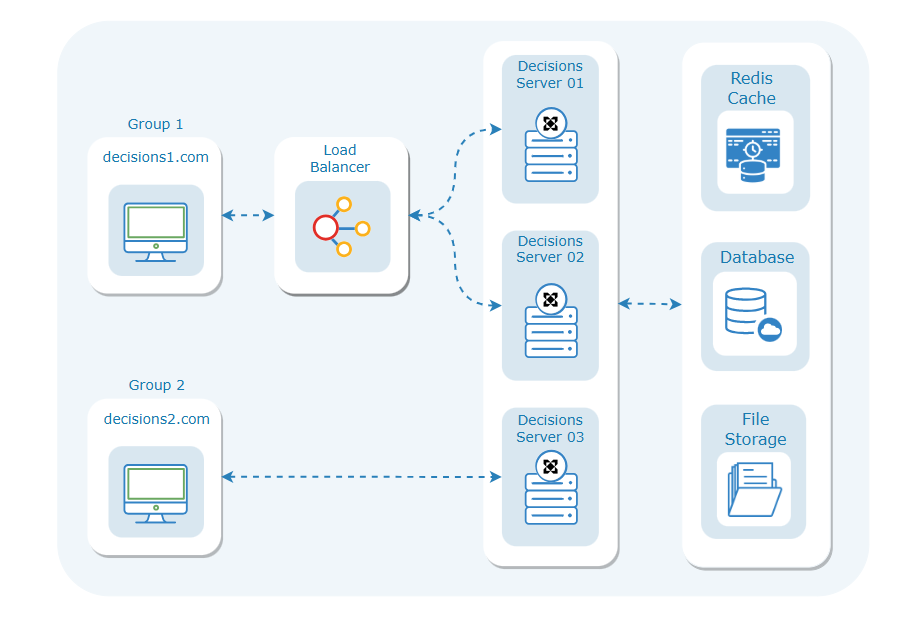
This deployment method establishes a cluster configuration with multiple servers, each assigned a unique IP address and having a common Load Balancer (LB) URL. The majority of users are directed to the cluster through the Load Balancer URL, facilitating load balancing across a few servers.
Simultaneously, a specific group of users is routed directly to a single server within the same cluster. This server, despite being part of the overall cluster, has its own URL. This tailored setup is designed to provide a dedicated environment for this particular user group.
Each server in the cluster maintains its individual URL, enabling direct access. The Load Balancer URL serves as the main entry point for the majority of users, while the specific user group accesses their designated server directly.
Cluster with a Backend Heavy Server
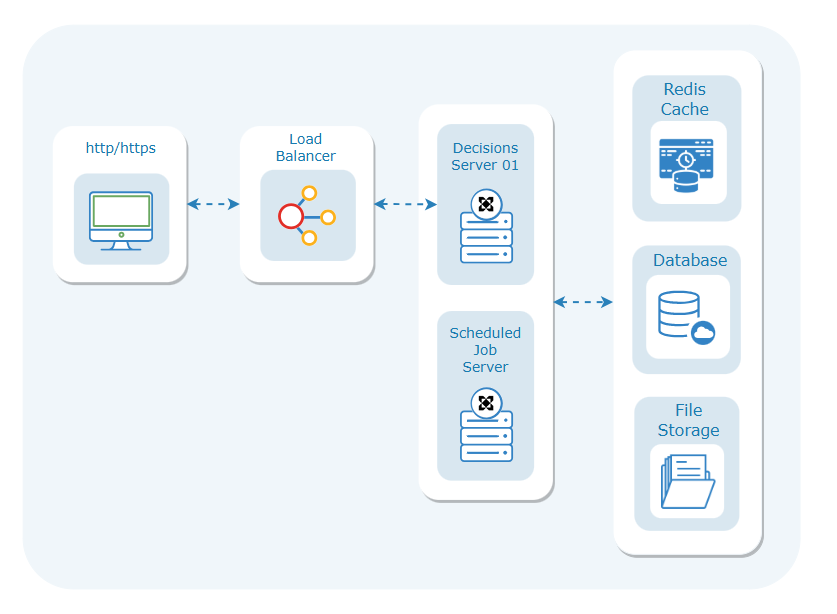
In this deployment method, a cluster environment is established with multiple servers. All the incoming client requests are initially directed to dedicated servers within the cluster through a Load Balancer.
Within the cluster servers, there is one server dedicated to executing heavy background workloads. This Server serves as a specialized resource for activities that might be resource-consuming or time-sensitive, such as running scheduled jobs and batch processing.
Unlike the cluster servers, the backend server does not directly receive requests from clients. However, in the case of a failure in one of the cluster servers, the Load Balancer can be configured to redirect incoming web traffic temporarily to the backend-heavy server.
Disaster Recovery
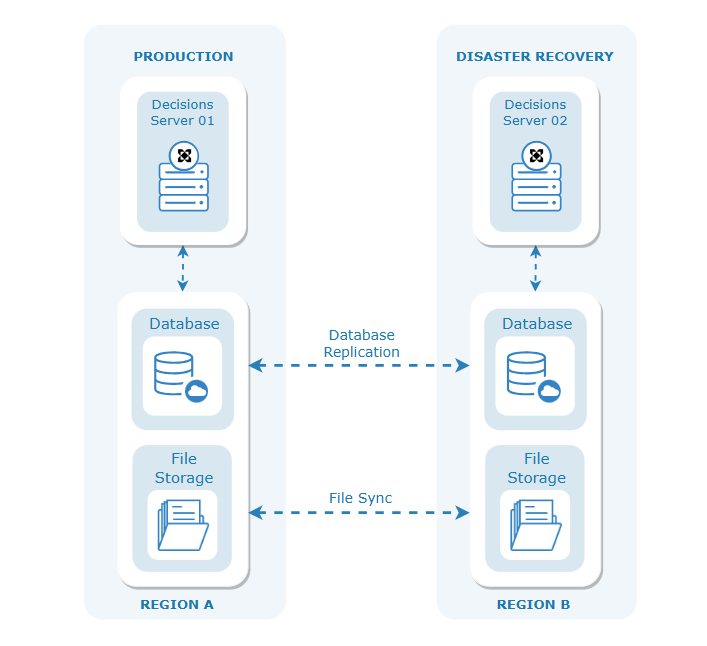
A Disaster Recovery (DR) Server is typically a duplicate of the primary server in a different location. In the case of a "disaster" event on the Primary Server, the DR server ensures that the application Server maintains uptime and that the data is protected. For more information, refer to Decisions Disaster Recovery Architecture.
Learn Next:
Learn how to set up a two-node cluster setup: Setting up a Cluster server